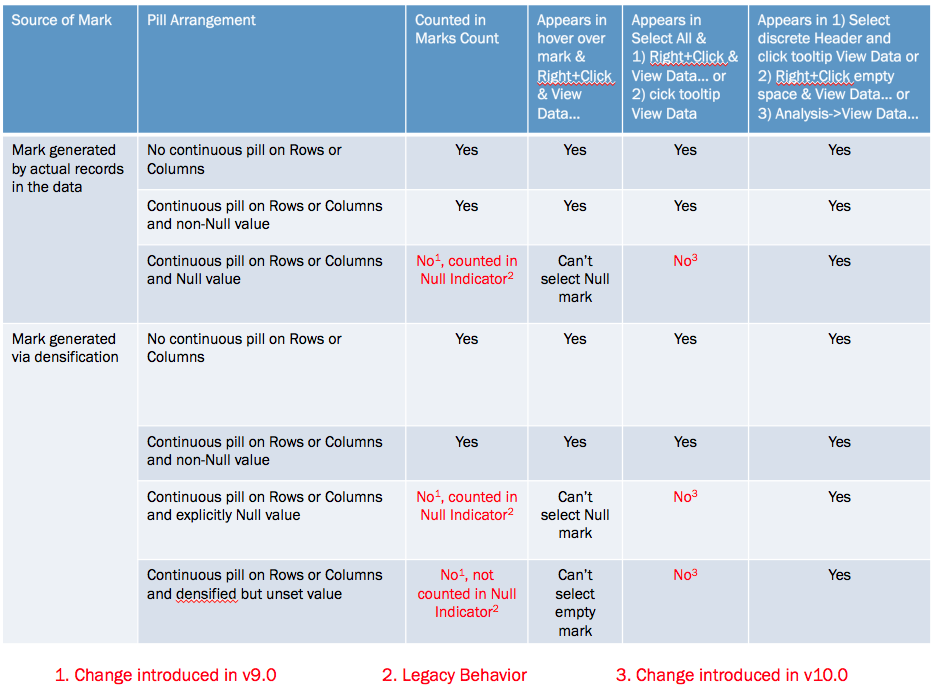
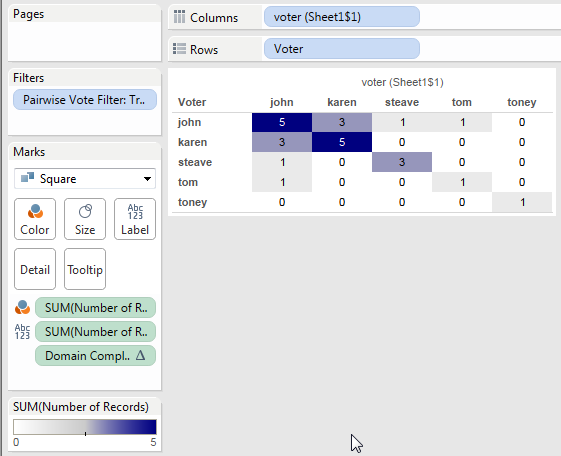
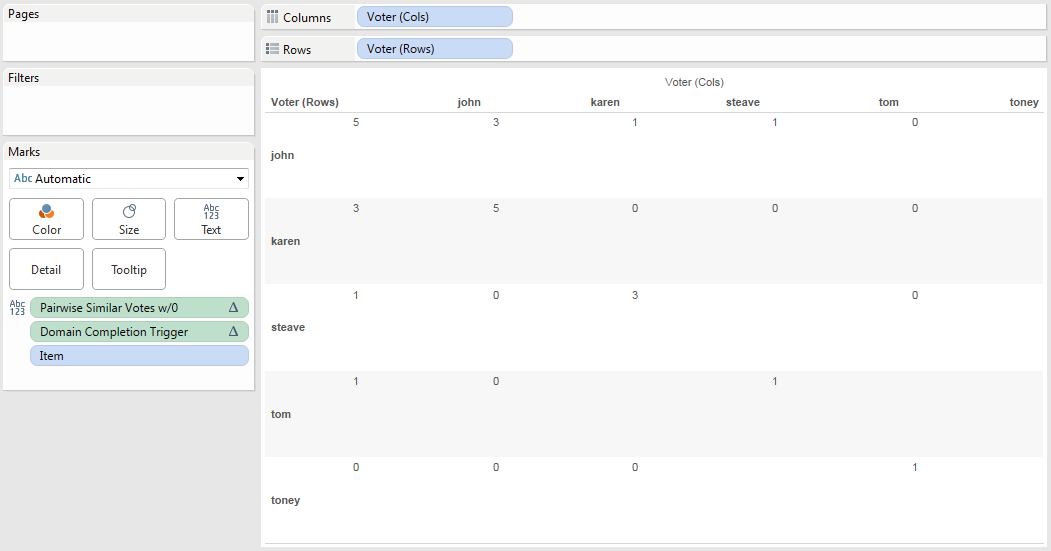
Note: this post uses a lot of animations and might be slow to load. Also the post was updated about 2 hours after publishing thanks to a tip from Pauli Isaacs @ Tableau about thinking about viz Level of Detail and what makes a markID.
I use a heart rate variability monitor and yesterday I was watching the graph on the app (sample below):

At first I was thinking of this as a “pulse rate” visualization but that style of monitoring has the trace of the pulse rate going from left to right, and then I realized it’s more like a seismometer or lie detector where the trace is drawn on the right while the paper is pulled to the left.

It takes a little bit of data preparation but we can get that effect in Tableau with the new #VizAnimations animated transitions feature coming in v2020.1. Here’s a view using climate data from the Met Office Hadley Centre showing 170 years of variance from the 1960-1990 global mean temperature:

I really like how having the marks “come in from the right” makes it seems like something is happening “right now”, and as the marks get to the late 20th century to the first couple of decades of the 21st the rising temperature change has a bigger impact. This kind of effect wasn’t really possible in earlier versions
Read on to find out how to apply this to your own data!
Overview
There are several steps to this method:
- Identify the dimension that you are using on Pages and the sort order. In this case that’s the Year and we’re going in ascending order. Then pad out the data so that each of those values of that dimension has all the data from the preceding values. So for each Year we’ll do a self-join to get the prior years.
- Create calculated fields to identify the latest/last value of the dimension on Pages and create a common x axis.
- Adjust the animation speed so that it doesn’t overly animate.
- Create calculated fields to act as a display x axis.
Note that technically this method will work for versions of Tableau prior to v2020.1, however with the animation controls it’s smoother.
1. At the core: a self-join to pad out the data
If you’ve ever tried to use the Pages Shelf in Tableau to draw a line mark over time you’ve ended up with something like this:

There’s a workaround where instead of using a line mark type we can use circles or something else and turn on Show history for Pages with mark trails and get a “line”, but the color of the trail depends on the color of the current mark, so the Color Shelf isn’t very useful:
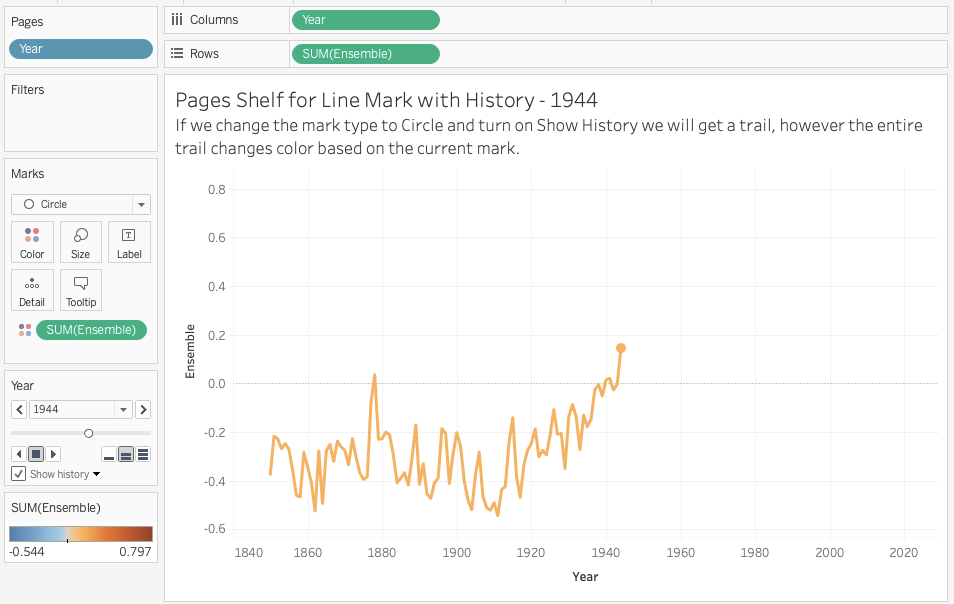
Also if we hover over the mark trail there is no tooltip since there’s only one mark displayed.
Now a way I like to think of the Pages Shelf in Tableau is that it’s like a flip book:

The Pages Shelf is slicing the view into a set of “pages” based on the values of the field(s) on Pages. Since Year is on Pages that means we see one year for each Page, and in this case since Year is the only dimension in the view (setting the viz level of detail aka vizLOD) there’s only one mark for each year.* Mark trails are a convenience that Tableau adds.
* I’m skipping the other factor in the number of marks that is the number and layout of continuous fields on Rows/Columns and measures on Measure Values. #tableaunerdybits
Therefore if we think of going left to right with the years and adding a mark for each additional year of data what we really want to do is display all the years preceding each year as we add each new year. For example in this data set in 1850 we just have 1850, in 1851 we want to display the data for 1850 & 1851, in 1852 we want the data for 1850, 1851, and 1852, and so on. So we need to pad out 1851 with two years, 1852 with three years, and so on.
I term the field that we’re paging by the “Page” field, so “Page Year” in this case, and then the version that is getting displayed the “Display” field, so “Display Year” in this case.
The way we can set up this data source in Tableau is with a non-equi-join on the Year, which is supported in Tableau Desktop and Tableau Prep for most all data sources:

Note that the non-equi-join is doing a form of cross product on the data, so if you have a lot of original data you may need to aggregate first using a custom query or view, or Tableau Prep or some other tool. Here’s a screenshot of the resulting data, not the replication of the Display Years across the Page Years:

Once we’ve got that then in a few clicks we can get a left to right animation that preserves the color, has tooltips, etc. (This animation is running slower because it’s using default settings).

2. Setting up the right to left seismograph animation
In order to build the desired view we can’t just reverse the axes because we need to preserve the time order of the data. What we really want to do is draw the first mark (1850) at the right-most edge of the x axis. Then for the next Page Year 1851 we want to draw 1850 just to the left and then 1851 at the right-most edge, and so on.
Another piece to know about the Pages Shelf is that it draws all of the discrete headers & continuous axis ranges in advance to the full set of values/widest extent. Therefore we need to make a common axis for all of the marks. This leads to a level of abstraction where instead of plotting the marks based on the year we’ll indirectly do that using some math where the first Page Year & Display Year 1850 is at position X, then in Page Year 1851 the Display Year 1850 will move to position X-1 (i.e. to the left) and Display Year 1851 will be at position X, and so on.
To do this I created a Max X Position calculation with using a FIXED level of detail expression and the formula {FIXED : COUNTD([Page Year])} to identify the number of years.
Then the X Position calculation has the formula [Max X Position] – ([Page Year] – [Display Year]). This appropriately offsets each year, as in this workout view:

I also added a Year Label calculation with the formula IF MIN([Display Year]) % 10 = 0 THEN MIN([Display Year]) END, this will be used later to simulate an X axis.
A couple of notes on this:
- This formula is assuming that the dimension used on Pages is sequential and has no gaps, if there were then you’d need a different calculation for the Max X Position.
- It could also be possible to get the desired formula using a series of table calculations (and potentially have higher performance in some situations), in this case I skipped that due to the complexity of the calculations; directly using the Year values in the calculations feels more “direct” to me.
With that in place we can use the Page Year on Pages, the Display Year on Dtail and ATTR(X Position) on Columns and see the view going from right to left:

We’ll fix the X axis further below, the next step is to get the desired animation behavior.
3. Moving from “worm-like” to fully “sliding”
With the default animation settings (note this is the v2020.1 beta, the final display might change) as the new marks are added to the right the animation slides left, but the right-most mark is “extruded to the right, then up or down” and looks to me like a worm searching for food. This is due to the Sequential animation that is animating all the marks in sequence.
The solution is to change the animation Style to Simultaneous, and personally I like the look of changing the Duration to a Custom setting of 0.1.

Here’s a GIF with the revised setting:

Now we’re getting somewhere!
4. Setting up an X axis for display
The last piece is to set up a working X axis. Since the X Position calculation is “fixing” the X axis for the Pages Shelf we can’t just use that X axis, instead we need something else. In this case I’m turning to a labeling technique that I learned from Ramon Martinez’s Overweight & Obesity viz Workbook: Overweight and Obesity across Countries where we use a dual axis. In this case the synchronized second axis is using a type in calculation to set the Y location and then the Year Label calculation is on Text. Since the Year Label calculation only returns every 10th year then it appears to be a label:
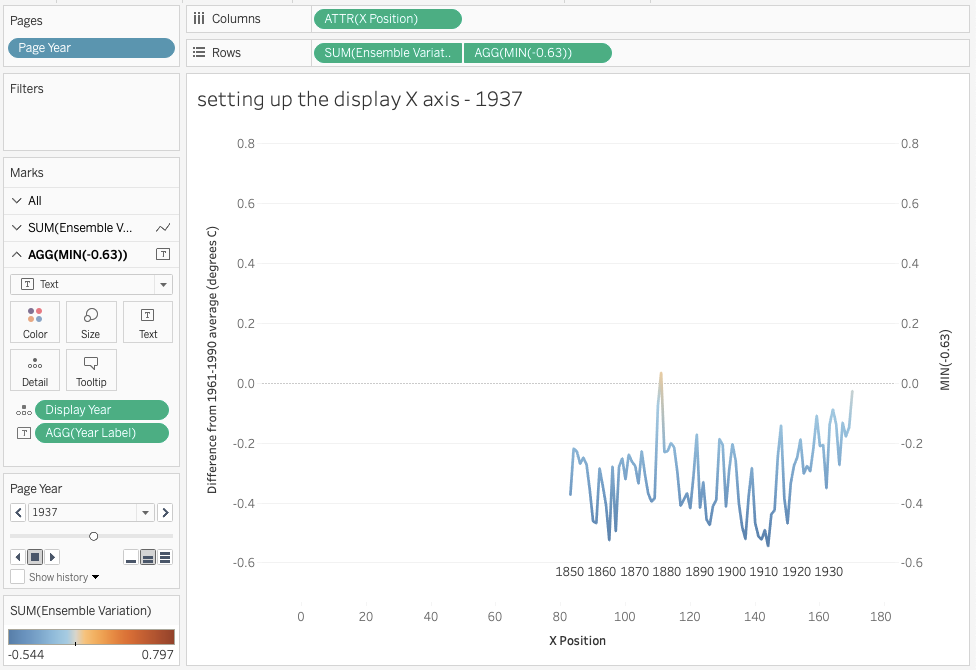
After building & verifying that it works then we can turn off Show Headers and do other formatting to get the final view:
Conclusion
As I’d written earlier in this post I really like the effect of the marks coming in from the right instead of the left as a way to help telling the story of the data; besides making for a common “entrance” for each new year’s data the sliding effect of moving the earlier years’ marks to the left helps remind me of the “what happened before” and keep that trend in mind, which in the case of climate data is getting quite extreme. I’ll definitely be using this method as time goes on.
I’ve also got a couple of ideas for future exploration…the first is to build a truly “moving window” like we see in an ongoing seismometer or polygraph readout. The second idea is to extend the “axis for display” concept to enable custom zoom effects on the Y axis to help draw attention to changes in the data.
Here’s a link to the packaged workbook on Dropbox: global temp variance seismograph.twbx (I’ll post to Tableau Public once it’s updated to 2020.1).