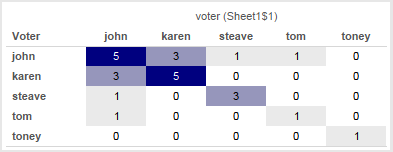
I got a question recently about wanting to use an action in Tableau to set a parameter. For example in this view below the goal is to hover over a one of the bars below to send the action to the circles on top and use that value to color the marks, change the shape, etc. In this case what we want to do is some sort of evaluation like [Circles Continent] = [Selected bars Continent] to be able to flag the selected continent and treat it differently, just like we would if we had something like [Circles Continent] = [Continent Parameter].
But for actions that cross worksheets all we have are highlight & filter actions. Here’s what happens with a highlight action:
Tableau’s highlight is limited to greying out the non-highlighted marks and being able to optionally display text.
And if we try a filter action we are even more stuck:
The filter action removes all marks but the selected mark which then breaks the rank table calculation, positions the mark in the wrong place, and doesn’t really let us do things like change the selected mark’s color vs. the other marks.
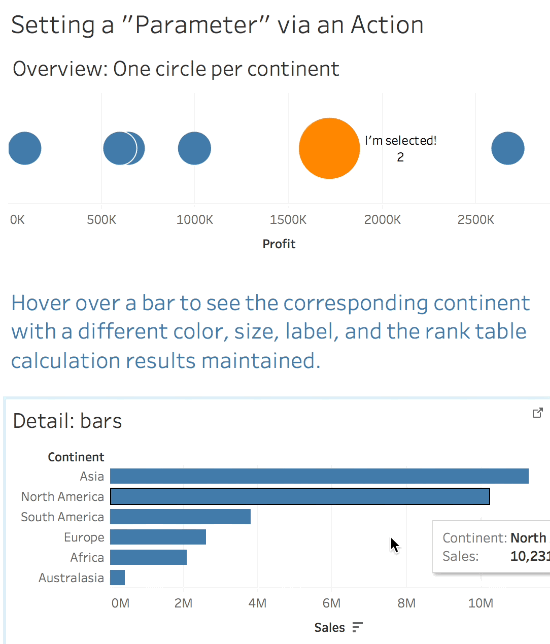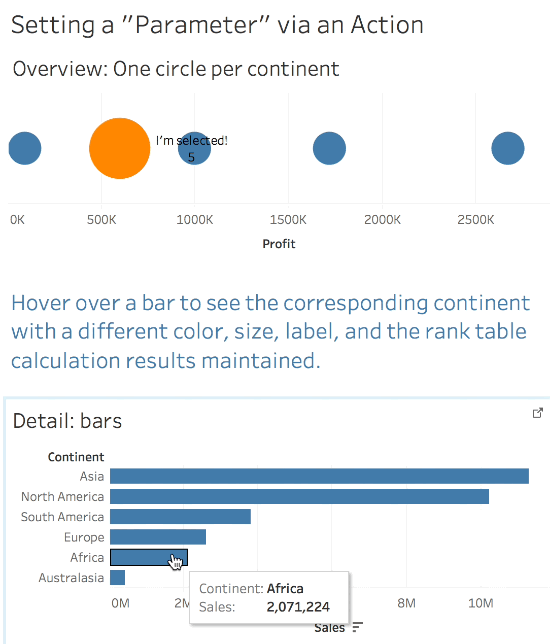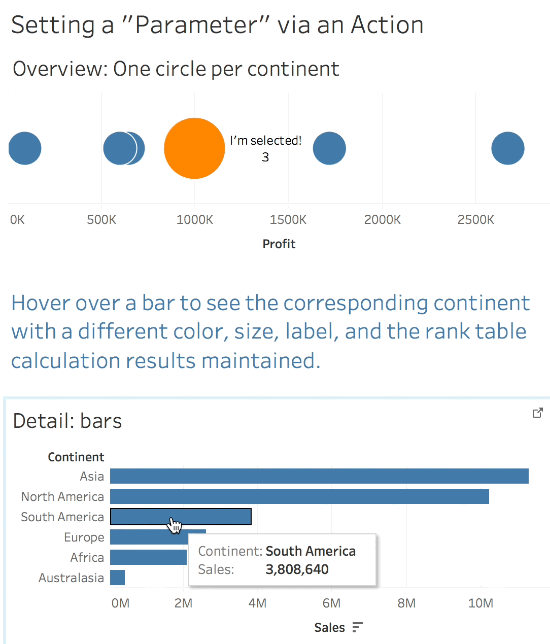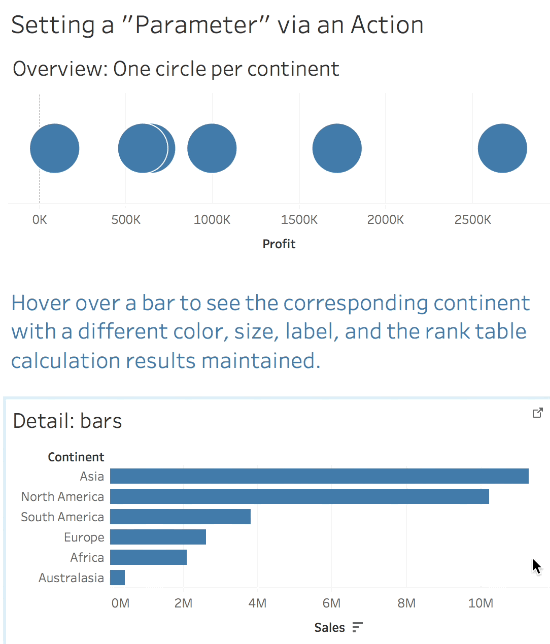
So Tableau doesn’t have an action to set a parameter value so we’re kind of out of luck…or are we? Try out this viz, you can hover and see the color and size change while the rank value is still preserved:
Now you can get this kind of effect using Tableau’s JavaScript API, this was done without using any JS at all. Read on for an explanation of how you can do this for yourself! Also thanks to Rody Zakovich, he gave some feedback to this and came up with some great extensions that he’ll be posting about!
A caution for Tableau newbies: this uses some relatively advanced data preparation, Level of Detail expressions, data blending, filter actions, understanding of the difference between the grain of the data and the viz level of detail, and knowledge of Tableau’s order of operations. If those terms don’t mean anything to you then you might want to start out by learning about those first.
Tableau is a Data-Driven Drawing Engine
The key to all of this is that fundamentally Tableau is a data-driven drawing engine. By that I mean that what we see in the viz and available interactivity are dependent on the data. So if we feed the right data to Tableau we can get it to do (al)most anything we want. For example in a post from last year I set up waffle or unit charts inside a map.
In this case what we’re wanting to do is change Tableau’s interaction behavior across worksheets. Looking at our options for interacting across worksheets in a workbook:
- Highlight actions can identify specific values have a very specific set of behaviors around appearance so we can’t change that.
- Filter actions can identify specific values in the target viz but remove other values.
So there’s a loophole in filter actions…filter actions remove other values, but since the origin & targets of the filter action are coming from the data if we feed Tableau the right data we can have it keep what we want and no more. So in this case we just need to feed Tableau more data (as in copies of the data) so that after the filter action takes effect we have enough data to identify the selected & non-selected marks. Here’s a description of what I mean:

How I think of this is that we’re starting out with i continent values and what we’ll do is expand that out to some number j continent values (actually 2i or i*i), then the filter action will cut that number down to a manageable number k continent values that we can then use calculations to identify the selected and non-selected marks.
Introducing the Scaffold
A scaffold is used in building construction, and in Tableau a scaffold data source is one that helps us get the data “just so”. In Multiple Ways to Multi-Select and Highlight I did a version of this where a union was used to give enough data so that way a mark could be highlighted. That required a full union of the data which can get prohibitively large, so for this method we’ll use a scaffold source that has just the values we need, and then when we want measures from the underlying data we can use a Tableau data blend.
The scaffold uses multiple copies of the list of the values that we want to filter for (Continent in this case). Now if you just have a “flat” table of data and don’t have a separate unique list of values then there are multiple ways to get one, please see Creating a List of Values in Tableau from Text and Excel Sources. I’ll be using
Once you have the list there are two different scaffolds you can use: One uses a cross product (i.e. for every continent there is every other continent), the second uses a union (thanks to Rody for that suggestion and demo). I’ll go through the cross product scaffold first because that’s a bit easier to set up than the union.
Using a Cross Product Scaffold to use a Filter Action as a Parameter
This section goes through the cross product scaffold. A cross product is also called a cross join or cartesian join or Cartesian product and a simple description is “for each value of A return each and every value of B”. So if we start out with the two values [A1, A2] and three values [B1, B2, B3] then we get the six combinations [A1B1, A1B2, A1B3, A2B1, A2B2, A2B3].
In this case we’re building a cross product of the dimension we want to build an action on and for this example we’re using Continent so the cross product will be 6 continents * 6 continents and end up with 36 rows in the scaffold. It’s important that the scaffold only has one record for each combination, if it has more than one record then the calculations below will break and alternative formulae would be required.
I’ll explain a little further about how this ends up working down below.
Creating the scaffold and setting up initial interactivity
- In Tableau connect to your original data source, in this case Superstore.
- Followed the instructions for creating an aggregated extract source from Creating Lists of Values for Tableau from Text & Excel Sources. For this next step I used the Continent dimension. Note where you saved the extract.
- Connect to the extract (.tde or .hyper file) in Tableau.
- Drag a second copy of the extract onto the canvas.
- In the join window set up an inner join with two join calculations so the join is 1 = 1.

- Rename the copy of the dimension to something useful, I used xprod continent. (xprod is short for cross product).
- Rename the data source to something useful, I named it xprod Continents.

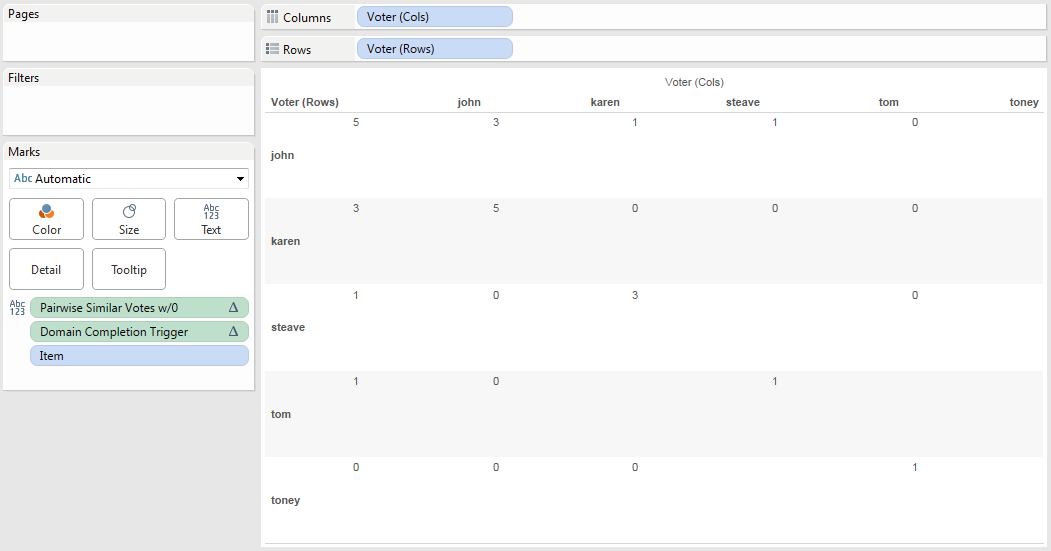
- Create a worksheet for the target using the scaffold (xprod) source as the primary with any necessary fields from the secondary source. This view requires the dimension & xprod dimension to be somewhere on the viz. To help see what’s going on I used a crosstab to start. Note that the xprod dimension is not in the compute using of the rank table calculation since there are multiple copies of the data.

- Connect to your original data source.
- Create the origin worksheet, in this case it’s a simple set of bars:

- Build a dashboard with the origin and target sheets.
- Add a filter action as a Select filter and and add a filter that for the source field uses the original dimension from the raw source and for the target field uses the xprod dimension from the scaffold source from step 6.
Here’s a demo:
How does this work?
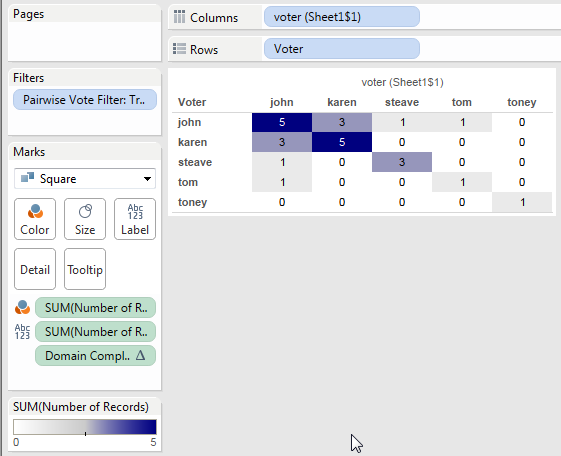
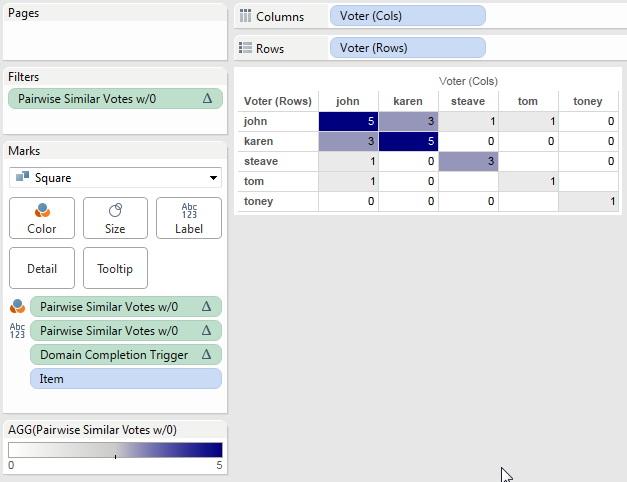
The scaffold source has 6 copies of the data, one for each xprod Continent. The filter action targets the xprod continent so when the filter action is triggered only one xprod Continent remains, and because we’ve multiplied the data there are the 6 Continent values remaining.
This leaves us with two useful attributes for each mark – the Continent, and the xprod Continent that identifies the selected value. The xprod continent is effectively the [Selected bars Continent] or [Continent Parameter] that we originally wanted to be able to do evaluations like [Circles Continent] = [Selected bars Continent] or [Circles Continent] = [Continent Parameter], only we had to do some extra data preparation to get there!
Identifying Selected Marks for Setting Color, Size, etc.
Now to we can do the evaluations to identify the selection status. There are three states to track:
- No selection made at all (which is something we can’t do with a regular parameter)
- The selected mark
- The non-selected marks (when there is a selected mark)
When there is no selection at all then there are 6 xprod continents for each Continent so we can count those and be able to flag the selected/non-selected state. Then if a selection is made the Filter Action reduces the data to only one value of xprod continent so we can test for that to identify the selected mark vs. non selected marks.
Here’s the Selection Status (xprod) formula used in the scaffold source:
//given the scaffold source COUNT(continent) across the data will return more than
//1 when the scaffold isn't filtered
//this uses the ability of EXCLUDE LOD expressions to be evaluated as
//record level calcs before they are aggregated in the view
IF {EXCLUDE [xprod continent]: COUNT([Continent])} > 1 THEN
-1 //no continent selected
ELSE
// identify selected continent
IF [Continent] = [xprod continent] THEN
1 //selected
ELSE
0 //not selected
END
END
With this flag now in place we can create additional calculations that can be placed on Color, Size, Shape, Label, Tooltip, etc. or even elsewhere in the viz.
For example here’s the Highlight Text calculation:
IF [Selection Status Flag (xprod)] = 1 THEN "I'm selected!" END
This only returns “I’m Selected” for the selected mark and Null for everything else. By putting this on Label it only appears when the mark is selected and can be used on Color as well. Note that it uses the ATTR() aggregation because the Selection Status Flag (xprod) is using an EXCLUDE LOD expression.
I created another calculated field for Size and some customization of the Size so that the nothing selected state has a mid-size neutral state, the selected mark is large, the non-selected marks are small. Here’s the completed viz:
Setting up with Select and Iterating
A couple of notes on setting these calculations up in the view – since we are using fields that have different results depending on the filter action status we will need to do an iterative process. For example when using Highlight Text on Color I needed to put the field in, trigger the filter action as a select action (so it would stay in place when I moved off the mark), then set the color for the selected mark, then verify everything was working by turning the action on and off, and then finally making the action a hover action.
Removing the Extraneous Scaffolded Marks
If we select all the marks in an unfiltered/non-selected scaffold view there are 36 marks – behind each Continent mark we can see there are the scaffolded continent marks from the xprod continent dimension. Personally I don’t like views that have extra marks kicking around for the following reasons:
- The more marks Tableau has to draw the slower the viz.
- Even though the marks are hidden they can cause confusion on the parts of users as they interact with the viz.
- The extra marks will be part of any viewing of summary data or data downloads and that can be especially confusing.
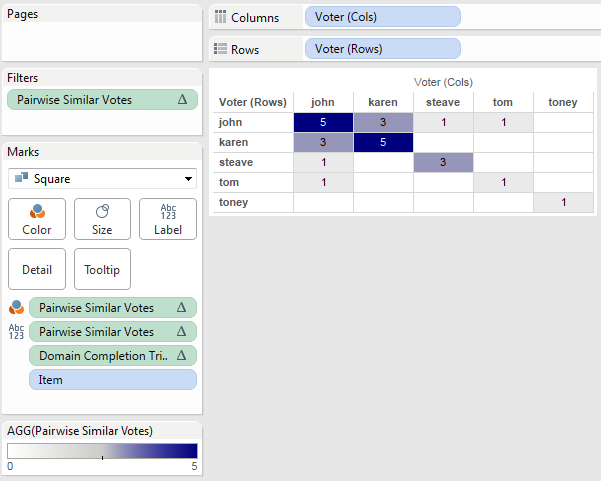
So how can we filter out the extraneous marks? This is where knowledge of Tableau’s order of operations, the viz level of detail (vizLOD), and filter actions comes into play. ~~link to documentation. The vizLOD is Continent and xprod continent and when there’s no filter action there are 6 xprod continents for each Continent, whereas when the filter action is activated there is 1 xprod continent for each Continent. Now the filter action is applied as a record-level aka dimension filter in Tableau’s order of operations ~~link so we need to use a filter that comes after that which could be an aggregate filter, a table calculation filter, or (as in this case) and INCLUDE or EXCLUDE LOD expression-based filter. Here’s the formula for the Remove Extra Marks (xprod) calculation:
[xprod continent] = {EXCLUDE [Continent], [xprod continent] : MIN([xprod continent])}
This uses a variation of the technique from my earlier post on identifying a dimension at a lower level where we’re using a Level of Detail expression to compute a result as an aggregate and then comparing it a record level. In the filtered view we know there’s only one xprod continent for each continent so that works out just fine.
~pic of selected
In the unfiltered view the EXCLUDE LOD will return the first xprod continent (probably Antarctica) and then only that one is kept while showing the 6 continents.
~pic of not selected
With this filter in place we end up with only 6 marks either way and have removed the extra marks added by the scaffolding to get a nice clean viz.
Final Notes on using a Cross Product Scaffold to use a Filter Action as a Parameter
This is not a technique for the faint of heart, it’s using a wide range of Tableau’s functionality to get a specific set of user interactivity. So it might not be for you. In building views like this for me where I’ve worked out the details of how the calcs need to work the most challenging part is often building the scaffold source. For example if you have hundreds or thousands of values of the dimension(s) you need to scaffold then the cross product can get prohibitively large, and for that we’ve got the alternative of using a union, we’ll cover that in the next section.
Using a Union Scaffold to use a Filter Action as a Parameter
Rody pointed this out to me as an option, this method uses a union’ed scaffold source instead of a cross product and a filter action whose filter pill is set to Exclude. So the scaffold source can be a lot smaller, but the set up is a little more complicated.
Overview
For this method instead of having N sets of values in the scaffold there are only 2 sets of values. We set up special calculated fields in the scaffold and the original data that will enable the filter action to exclude (remove) from a selected value from the scaffold so we can use that difference to detect what has been selected.
How to Build the Union Scaffold
Here’s how to build this, this is a slight variation on the instructions for an aggregated extract from Creating Lists of Values for Tableau from Text & Excel Sources:
- In Tableau connect to the raw data source.
- Union the raw data to itself.
- Create a worksheet that only has the necessary dimensions plus the Table Name and Sheet dimensions.
- Create an aggregated extract per the instructions in the link. ~pic
This ends up with a scaffold source where there are two copies of the list of values, like this: ~pic
Setting Up Interactivity
- In the original data source create an ExcludeOrigin field in the original data with the formula
'~~' + [Continent]. - Create an origin worksheet with the Continent & ExcludeOrigin fields.
- In the scaffold source create an ExcludeTarget field with the formula:
//there's an implied ELSE Null, the Null values are the ones we will ultimately keep IF [Table Name] = 'Data1' THEN '~~' + [Continent] END
- Build the target Scaffold sheet with Continent and ExcludeTarget as dimensions. Note that there are 2N marks where N is the number of Continents with 2 values of ExcludeTarget for each. ~pic
- Add any measure(s) you want from the original data via a data blend.
- Create a dashboard with the two worksheets.
- Add a filter action on Select from the origin worksheet to the target worksheet that goes from the ExcludeOrigin field to the ExcludeTarget field. ~pic
- Trigger the filter action by selecting a mark on the origin worksheet.
- Go to the target worksheet.
- Right-click on the Action (ExcludeTarget) pill on Filters and choose Edit Filter… The Edit Filter window appears. (If you don’t see the pill on Filters then you haven’t triggered the Filter Action).
- Click on Exclude, then click OK. ~pic
- Go back to the dashboard and click on different marks on the origin worksheet, you’ll see the target update.
To explain how this works we have to keep in mind that there are effectively two states:
- When there are no marks selected in the origin worksheet then nothing is excluded from the target sheet and we see all N (12) marks from the scaffold.
- When a mark is selected in the origin worksheet then the corresponding mark with the non-Null value of ExlcudeTarget is removed from the viz, leaving us with N-1 (11) marks remaining.
Identfying Selected Marks for Color, Size, etc.
Because this scaffold is built using a union the detection of mark selection status works a little differently, here’s the formula for the Mark Selection Status (union) field:
//In the union scaffold there are two states: all rows exist or one has been filtered out by the selection
//if all rows exist then there are 2x the number of continents and we can test for that
IF {EXCLUDE [Continent], [ExcludeTarget] : COUNT([Continent])} % 2 = 0 THEN
-1 //no selection made
ELSE
IF {EXCLUDE [ExcludeTarget] : COUNT([Continent])} = 1 THEN
1 //the selected value
ELSE
0 //the non-selected values
END
END
Essentially since we’ve doubled the data then we can use the modulo (%) operator to detect that doubling and identify the no selection status, then by counting continents we can find out whether are 1 or 2 records and identify the selected/non-selected marks.
From here the other calculations are all the same as for the cross product scaffold except for the Remove Extra Marks calculation. In that case the Remove Extra Marks (union) formula is:
ISNULL(ATTR([ExcludeTarget]))
Note that we could just use ATTR([Exclude Target]) and filter for Null as an alternative…this is one of those cases where I like having a separate calculated field because then by the name of the field I can give the viz maintainers a chance to understand what is going on.
Here’s a completed dashboard using the union, you’ll find the interactivity to be the same as the cross product version:
Conclusion…or…When Should I Use This?
When I’m building a dashboard and my users are wanting interactivity that is more than what Tableau immediately offers I go through a mental checklist:
- Is the goal something that we can pull off using highlighting, sheet swapping, filter actions, parameters, sets, etc.?
- Is this the only “ask” for additional interactivity or are there other cases for this dashboard where the desired user experience is pushing the boundaries of what is provided in Tableau? If so are there resources to use some JavaScript and Tableaus JS API?
- Only then do I start considering more complicated methods that require more data prep and configuration like the one presented here.
Here’s a link to the Filter Action as Parameter dashboard on Tableau Public. Hopefully you learned a bit about how to take advantage of Tableau’s capabilities, if you have any alternatives or questions please ask in the comments below!