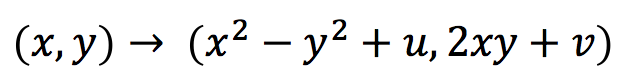Tableau’s data densification is like…nothing else I’ve ever used. It’s a feature that is totally brilliant when it “just works” like automatically building out a running sum on sparse data and mind-taxingly complicated when a data blend’s results go haywire because densification was accidentally triggered.
What I’ve historically taught users is to always ALWAYS look at the marks count in the status bar as a first way to detect when data densification occurs. Here’s Superstore Sales data with MONTH(Order Date) on Columns, Region and State on Rows, there are 499 marks and we can see that the data is sparse by the class that are missing Abcs:
If I add SUM(Sales) to the Level of Detail Shelf and set it to a Running Total Quick Table Calculation with the default Compute Using of Table (Across) so it’s addressing on Order Date then I see 576 marks and all the Abcs are filled in, this is Tableau’s data densification at work:
However, here are three additional views all still using the same pill layout and Quick Table Calculations showing three different marks counts (567, 528, and 456):
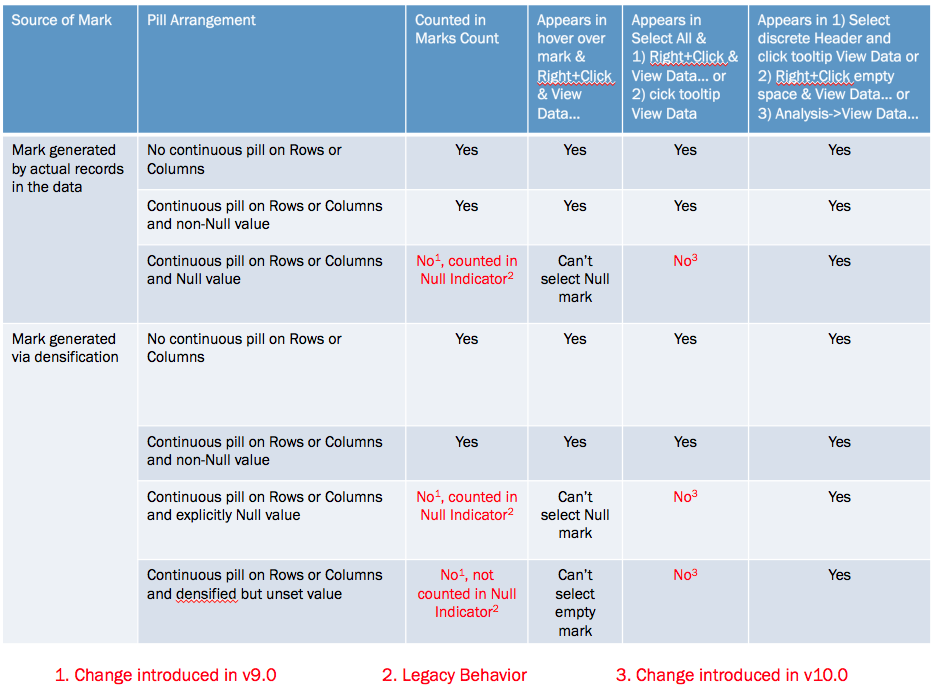
The marks count is changing based on a variety of factors, the different quick table calculations used (running total, difference, and percent difference) are a part of it but the underlying behavior depends on whether a mark is densified or not, the pill arrangement, and whether or not a densified mark has been assigned a value (including Null) or not. Prior to Tableau version 9.0 these all would have been counted in the marks count and the views would show 576 marks for each, Tableau v9.0 changed the behavior to only count the “visible” marks.
I’ll walk through the above there examples. In this one the Running Total has been moved from the Level of Detail to the Rows Shelf and there are 567 marks.
The reason why is that even though those combinations of Region, State, and Month have been densified for states like Iowa that don’t have any sales in the first month(s) of the year (more on how I know that below) those densified marks don’t have any assigned value (even Null) so they are not counted in the marks count nor are they counted in the Special Values indicator in the lower right.
In this view using the Difference calculation there are 528 marks and the Special Values indicator shows 48 nulls (528+48 = 576). In this case the Difference calculation is using the LOOKUP() function that is returning Null for the densified values.
Finally in this view using the % Difference calculation there are 456 marks and the Special Values indicator shows 120 nulls (456+120 = 576). In this case the % difference calculation is spitting out extra nulls due to divide by 0 results.
The difference is due to a change made in Tableau v9.0 where the marks count now only counts “visible” marks (Tableau’s term), where the definition of a “visible” mark is complicated, they are the “Yes” answers in the table below:
Now one of the ways I’ve been used to checking for densification is selecting all the marks (either by Right+Clicking and choosing Select All or pressing Ctrl/Cmd+A) and then hovering over a mark and Right+Clicking and choosing View Data… or waiting for the tooltip to come up and using View Data. For example here’s the select all View Data in v9.0 for the % Difference on Rows view, the yellow cells indicate where data was densified and there are 576 rows:
However, that doesn’t work anymore in Tableau v10.0, there was change made to the Select All functionality such that Select All only gets the “visible” marks, here’s that same view data in v10 and there are only 456 rows:
So Select All doesn’t work the way it used to, and the marks count can change in “interesting ways” (and we haven’t gone into what things like formatting Special Values can do), so what can we do to spot densification? There are three workarounds for this, all documented in the right-most column of the table above:
Select a discrete header or a range of headers, wait for the tooltip to come up, and click on the View Data icon.
Right-click in the view (but not on a mark) and choose View Data…
Use the Analyis->View Data… menu option.
All of these will show the densified values, here’s an animated GIF of selecting Iowa selected in the Difference on Rows view where we can see the two Null values:
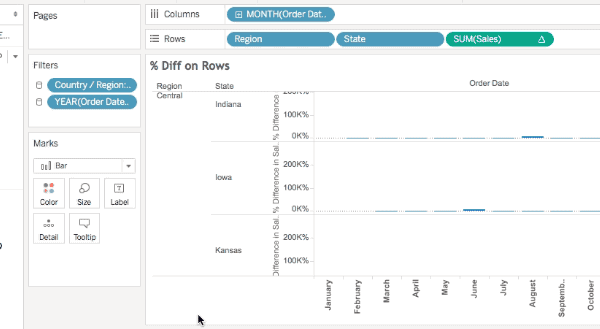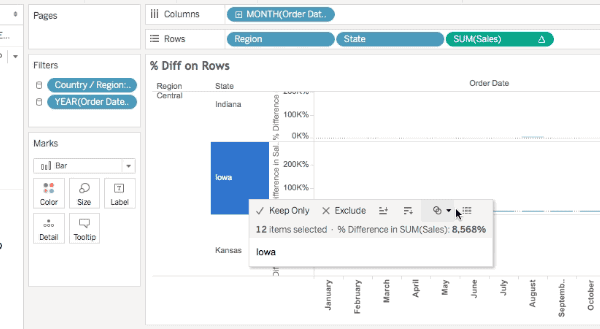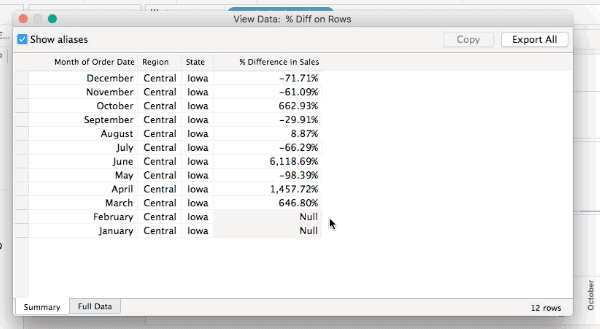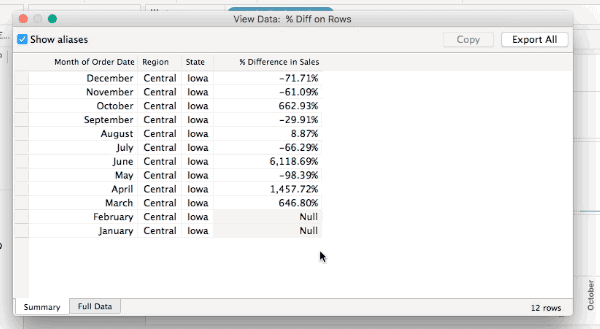
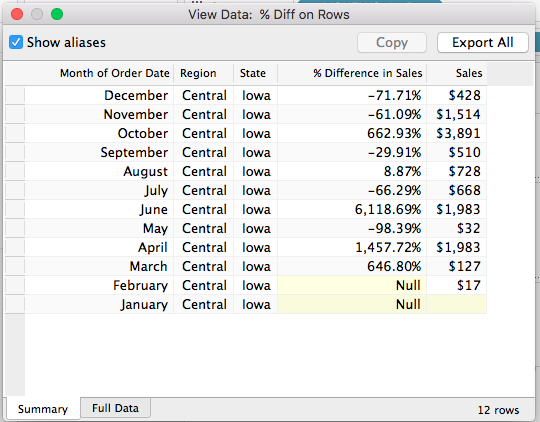
However only one of those is actually densified, to tell that exactly we need to add a field that actually has data. In this case I’ve added SUM(Sales) to the Level of Detail Shelf and the View Data for Iowa now shows that it’s really only January that is densified, since there’s nothing at all in the January SUM(Sales) cell:
Conclusion
The marks count is not a reliable indicator of the volume of densification and we need to resort to various selection mechanisms and the View Data dialog to more specifically identify how much has been densified. I’m not a fan of these changes: what I’d really like Tableau to do is to add a count of densified values to the status bar and details on what was densified to the default caption and the Worksheet->Describe Sheet… Until that time, though, hopefully this post will help you keep track of what Tableau is doing!
Here’s a link to the marks count workbook in v8.3 format (so you can open it up for yourself and see the differences in different versions).
Many moons ago I did a first post exploring the non-obvious logic of the most secretive of Tableau table calculation configuration options: At the Level. A few weeks ago I was inspired by a question over email to dive back in, this post explores At the Level for the five rank functions: RANK(), RANK_DENSE(), RANK_MODIFIED(), RANK_UNIQUE(), and RANK_PERCENTILE(). The rank functions add a level of indirection to the already complicated behavior of At the Level and I don’t have any particular use cases, so…
If you are like me and won’t rest until you understand every detail of Tableau’s functionality, then this post is for you. Otherwise you may find this post unhelpful and/or confusing due to extreme table calculation geekery. You have been warned.
The particular challenge with ordinal functions like INDEX(), FIRST(), and the rank functions is that we absolutely have to understand how addressing and partitioning works in Tableau, and then we tack onto that an understanding of how the calculations work, and finally we can add on how At the Level works. For the first part, I suggest you read the Part 1 post on At the Level, it goes into some detail on addressing and partitioning. To understand the rank functions here’s the Tableau manual for table calculations (scroll down to the Rank functions section). Finally, read on for how At the Level works for rank functions.
When I first saw Jonathan Drummey’s Orrery post I sat there staring at it for a few minutes. Wow, right? So when the idea occurred to me to remix this classic I spent a few days wondering if I was serious. Once I managed to push my mouth closed I wondered if Tableau was the right tool for this job. Tableau, I thought, is just a tool for working with and visualizing existing data.
The Orrery is computation driven; the position of the planets are computed on the fly in Tableau and the data source driving this piece of art is almost an afterthought. It could literally have been built on Superstore Sales, you just need a place to hang the results of computations. In the case of Jonathan’s Orrery, this structure comes in the form of a SQL query that generates a hugely redundant data set. In all it has 51,840 rows. There are 18 planets (counting the sun and various moons), 360 ticks for the frames in the animation and 8 wedges for the slices that make up the pie charts used to draw each planet showing day and night (best use of pie charts ever!), 18 x 360 x 8 = 51,840.
I’m two blog posts deep into domain padding and using Tableau as a drawing engine, so I was reasonably sure the Orrery could be replicated with fewer rows in the source data, and that doing so could add flexibility in the number of ticks and the number of pie wedges. Improving the structure slightly didn’t seem significant enough on its own. I decided to give it a go if only for practice, and as an excuse to dive into understanding the original, but set two requirements that would need to be met prior to declaring it blog-worthy: First, Jonathan would have to be onboard, which he was. Second, it would need to bring something new to the table. I think I succeeded in finding an interesting point of view, but it isn’t exactly a new one…
I’m going to put the earth back in the middle!
My Orrery is built on two datasets. One that holds a single copy of the solar system data, and another for the intricate clockwork mechanism that makes it all tick. I connect these via data blending in Tableau. This blend could easily have been avoided, but it seemed like a more natural way to find the data. I figure this setup would make it easy to apply to other solar systems without duplicating effort. The planet data has 18 rows, taken from any of the 2,880 identical copies in Jonathan’s workbook (I used wedge 1 of tick 1, not that it matters), the mechanical structure has 72 rows. Since blending is a left join, I’d call this 72 rows total, but if you say 90, I guess I wouldn’t argue.
Since recreating the Orrery I’ve discussed my approach with Jonathan, and learned he considered using domain padding for the original, but ruled it out because of performance issues. Tableau 8.0 and 8.1 included some performance improvements for Table Calculations, so it is likely this approach only recently became feasible. Both techniques have strengths and weaknesses, it isn’t clear to me that one is better than the other.
There is one small point I can claim as a genuine improvement, that is changing the Days/Tick parameter from an integer to a float. Large values are needed to get satisfying movement from the slow moving outer planets, but some of the fast moving moons require less than one earth day per frame to see a smooth orbit.
Before I get any angry emails, I should mention that the planets don’t travel in perfect circles (or even ellipses), and that the solar system is also moving around the center of the galaxy and that it is all expanding from some infinitely dense singularity, which exploded for some reason. I’m not a physicist. This is more of a classroom model, a shiny one made mostly of brass. My interest is more on perspective than perfect accuracy. If I had a beta of Tableau 8.2, I might have shot for ellipses; in Windows, meh… close enough.
Putting the earth in the middle is something I hadn’t seen a computer animation of. I knew the math could get complicated, which is why Copernicus and so many after preferred centering on the sun, but Tableau actually makes it pretty easy to change perspective. In fact, why just look at an earth centered solar system? What would it look like if we centered it on Venus or Mars? It turns out it is a lot crazier than I had imagined! Another surprise (though in retrospect it shouldn’t have been) is that from the perspective of slow moving outer planets the solar system model looks very similar to the sun centered view. I suppose this might develop over a longer time span than any I tried.
I started by taking perspective of standard heliocentric model, which is simplest math, both empirically and because I had Jonathan’s Orrery for reference. I then used a lookup table calculation so that the heliocentric position of the earth was visible to each of the other planets. Then, in what amounts to vector addition, I offset each planet by exactly the negative of the position of the earth. This puts the earth at the origin, and since an equal distance displaces each planet, the relative position is exactly the same in each frame. The history, on the other hand, traces out a very different path. A heuristic way to think of this, in terms of the clockwork orrery, is to pick the whole thing up by the earth, or some other planet, and holding that planet fixed while the mechanism, base and all continue spinning away as normal. Please don’t attempt this with your antique orrery, you will break it.
Trying to see things from two perspectives at the same time reminds me of optical illusions where you can see two possible pictures. With practice I can usually switch between perspectives quickly, but I can’t seem to see the old lady and the young lady at the same time. Why is that?
Since the trails give a historical record that is based on the center of the view, I thought it might be helpful to provide some landmark to compare it to another perspective. To accomplish this, I repeated this process of computing the position of a chosen planet to build a window that would dynamically remain centered. My original intent was that this window would follow the now moving sun, though again I found it interesting to approach with more generality, so the window can be centered on any planet or moon in the view. In any frame of the animation, the position of planets within these boxes is identical between the two models. Here is a video of simultaneous geocentric and heliocentric models:
I considered taking a shocking stand and arguing that the earth really is the center of the solar system, but the reality is that velocity is relative; for speed you need a fixed frame of reference. Imagine waking up on a train and seeing another train out the window that is travelling in the opposite direction. Both trains may be moving in opposite directions at 30 miles per hour, or just one train moving 60 miles per hour with the other standing stationary (or infinitely many other possibilities). To be absolutely certain of what is happening, the best approach is to look out of the window on other side. A stationary platform will clarify that your train is at rest and you’re about to miss your stop. When riding on a train, the earth is a fixed frame of reference from which we can discuss motion in an absolute context. The context determines the frame of reference, and generally this choice is so obvious you wouldn’t even realize you’re making it. When you consider planets, however, there is no handy universally agreeable point from which to gauge motion (at least not since Copernicus).
Often, regarding earth as a fixed point is preferable. Imagine trying to build a house or navigate to work while accounting for the spinning orbit of a planet that travels around the sun at 67,000 miles per hour. Most of us are unlikely to get further off this planet than an airplane ride, and planetary motion isn’t particularly relevant at that scale. Even taking a trip to the moon, my guess is that an accurate model of the solar system would be tremendous overkill. Any trip we take from our planet will begin with the same velocity and direction as the earth, and be subjected to the same gravitational forces for some time afterwards, so why does it even matter? Well, I think there is a deeper lesson in this story.
There is a famous quote of George Box, “Essentially, every model is wrong, but some are useful.” Finding out fundamental beliefs are wrong can be upsetting, or at least disorienting. Looking at the Venus centered solar system gives me some idea what it must have felt like for the first who pondered centering things on the sun. It also makes it easier to understand those who thought the idea was laughable.
Mathematical models are an important tool in science, including data science, but most models aren’t regarded as “the truth” until they are taken well out of their original context. I believe that as humans we are wired to search for the truths underlying our universe. I am anyway and there seems to be a strong historical case. But accepting mathematical models as such isn’t necessarily truth-ier than what came before. I do think the decrease in stake burnings is progress though.
The lesson here is one of complexity. I’m as guilty as the next guy of adding complexity to achieve a desired result, maybe more so. Something I’ve learned several times across several disciplines is that when you are adding layers to keep things working it is a good time to step back and check your assumptions. Changing your paradigm may result in something simpler, and while simplicity and truth are different things, they are both worth chasing.
So here is Orrery 2.0. Dynamic animation doesn’t work in Tableau public (currently) so please download for the full experience. Have fun experimenting with different centers and see some of the crazy orbits that evolve. Hopefully someone will enjoy this half as much as I did the original and a seed will be planted to push this even further. I can’t wait:
If you think my displacement approach is cheating and you’d like to go back to epicycles, or Ptolomey’s epicycles on epicycles (computers have come a long way since then, so this goes 5 epicycles deep), here is a Spiro-graph workbook to use as a starting point. The source dataset has only 2 rows; across 3 blog posts that brings my total to 6 workbooks, none of which has more than 100 rows in the source data. In fact, I believe that makes 106 rows altogether!
DNA can be expressed as a number, if say you wanted to upload yourself to your Tableau public account. Would you fit? There are 4 base pair possibilities, so this could be encoded in 2 bits; so with 8 bits in a byte you could store 4. There are about 3 billion base pairs in human DNA, 3 billion/4 = 750 million bytes or about 750 megabytes. So even in an uncompressed format you would fit well under the current 1GB storage limit of Tableau public! So future generations of data enthusiasts could download you as a packaged workbook, then using their advanced technology they could bring you back.
Hang on a second… can that be right? Windows 8 is at least 10GB, and it sucks; how is it I can be stored in less than 1GB? Well, there is more to you than written in your DNA, and I don’t just mean your experiences. Identical twins have the same DNA, yet they are different people. Our experiences shape who we are, but any parents of twins will tell you it is more than that. Even at birth, twins have different personalities. That could be hard to prove objectively, but they also have different fingerprints. So your DNA doesn’t dictate your fingerprints, at least not entirely. So where do they come from?
Math. DNA is already compressed pretty efficiently. Computing the number of cells in the human body isn’t strait forward but a recent journal article estimates it at 37.2 trillion. Also, that is just a count. Consider all the types of cells, their location, and connections to one another. Now that is a lot of data! Expressing this complexity as a number would be a lot trickier, and likely a lot larger (no, I’m not calling you fat).
Fractals exhibit a property that would be very useful in this type of compression. Fractals are remarkably complex structures that can result from a relatively simple set of instructions. The magic is in the process, not the underlying data, and the process can be expressed very compactly, often in a single equation.
When simple instructions create fractals or life, one byproduct seems to be similarity across different scales. Think of the branching in your blood vessels, or in a tree, smaller and smaller scale but with similar rules. If you cut off a piece of most fractals you end up with a structure that is no less complex than the original. If you zoom in, you can often see a very similar picture to the whole. There are a couple areas of math whose significance didn’t sink in for years after I studied them; fractal geometry is one such example.
Right. So how is this about Tableau? The dashboard below is driven by a dataset with only 2 rows. I guess building life might be a stretch, but it sure does look like it. For more of the details on how I’m pulling this off, as well as some other pretty images in Tableau, have a look at my post Creating data, multi-step recurrence relations, fractals and 3D imaging… without leaving Tableau. Feel free to skip to the pictures, but I do recommend 3D glasses for the last ones.
I’ve wanted to showcase more of the creations of other Tableau users, and in a lovely coincidence I recently got an email from Joe Mako sharing a workbook by Noah Salvaterra that blew me away. One way I approach Tableau is to think about it as a drawing engine for data, and in this guest post Noah takes that to new extremes. I’m excited to share what he’s done, and rather than say any more, here’s Noah:
The 3D Caveat
Showing Jonathan Drummey an early version of the 3D Tableau workbook, his response included some words I’ve reflected on since: “Just because I can, doesn’t mean I should.” The comment wasn’t disparaging, it was directed at examples of 3D pie and bar charts I’d built which I’ve since removed. I’m not a fan of 3D charts. Tableau is perfectly capable of doing 3D charts; they just weren’t built in because they tend to distort more than engage.
What follows is not meant as a point of view on best practices, rather it is an exploration of some techniques I’ve been playing with and thought others might find interesting (or at least pretty). These examples exists because they can; the jury is out on whether or not they should. I’ve done my best to keep this presentation light, however, deep concepts both in Tableau and math are discussed. Feel free to skip ahead and look at the pictures or ask me to clarify in the comments if you need more detail; it will not be on the test.
Now the 3D workbook is probably the most visually remarkable part of this post, so I’m saving it for last. To be clear though, when I say 3D, I mean 3D, not 3D-ish. We live in a 3D world, and while you can see artifacts of that fact in a photograph, photographs are generally 2d, as are “3D” charts in excel; they suggest 3D, having come from a 3D world by using shading and perspective. I’m talking about something that will step right out of your monitor like a good 3D movie (and hit you in the face if you lean in too close). Like with 3D movies, appropriate glasses are needed to get the full experience. I’ll give some instructions on where to find these and suggest a brief intermission when we reach that point.
Creating Data
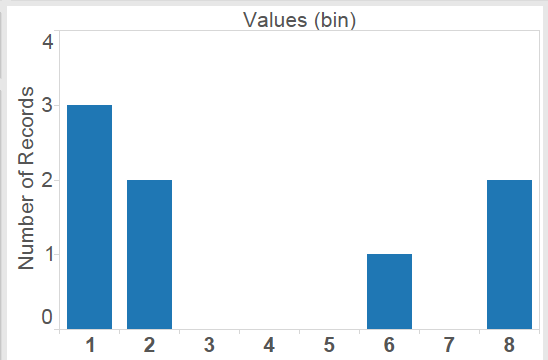
For some time after I started using Tableau, I believed the marks and the underlying data to be more or less the same thing. In fact there are several situations where marks are generated without having them in the underlying data! If this is news to you, don’t panic, everything will be fine. Consider a dataset with the values: 1,1,1,2,2,7,9,9. Frequencies for this data could be displayed in a few different ways; here are the two that seem the most natural:
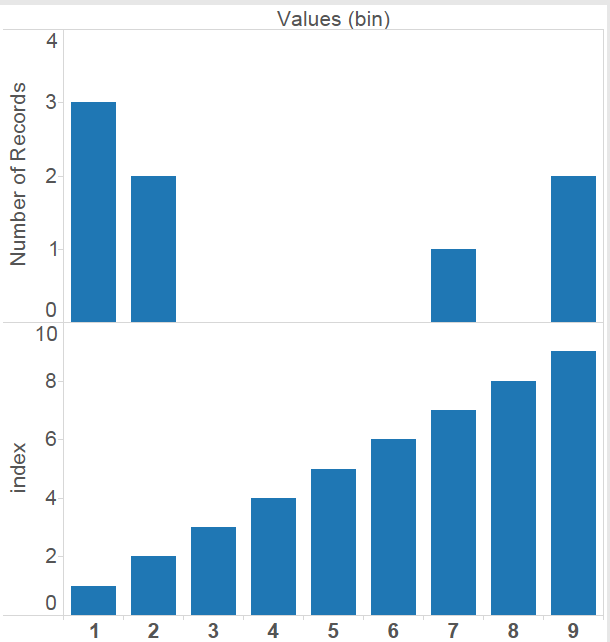
The second of these shows blanks for some values that didn’t occur in the original dataset. Like dates and date-times, Tableau Bins are range aware; that is, there is some built in awareness of there being bins that were skipped over. In this case the bin size is 1, and when “Show Missing Values” is selected, I get blanks for the empty bins that occur between my data points. This type of densification is called domain padding. There are several others, but those would take several more blog posts. The number of empty bins that could be created in this way is unlimited. These bins are empty, but they are accessible to table calculations, so if I create an Index computing across the table I get this:
The Index shows 9 points, though the dataset has only 8 rows and has data in only 4 bins. In fact, the largest dataset used for this post has 32 rows, well under the million rows of data allowed in Tableau Public, and with domain padding could become as many rows as Tableau Public would let us before it ran out of memory. In theory, any of the demonstrations should be possible to do with 2 rows of input data, but I’ll leave that as an exercise.
Multi-step Recurrence Relations
The LOOKUP(expression, [offset]) function in Tableau will return the value of another field or calculation at a different row. It shows up in the difference and percent difference calculations. With the offset argument it is possible to specify arbitrary number of rows back. A similar, and often confused function, is PREVIOUS_VALUE(expression) which looks back exactly one row in the current field or calculation. Along with domain padding, this started me thinking about recursion. While it would be possible to do simple 1-step recursion in this way, there is no second argument in the PREVIOUS_VALUE function, so more than one step back is off limits to this function.
The Fibonacci Sequence
0, 1, 1, 2, 3, 5, 8, 13, 21, 34,… each number is the sum of the last 2. While PREVIOUS_VALUE() gets us the prior one, there doesn’t seem to be a way to get back further. Note the Fibonacci sequence actually has a closed formula for these terms that would avoid the recursion, but I’m just using it as an example.
I like solving problems, but sometimes even a problem solved leaves a bad taste in my mouth. This is such a solution. I like it because it works, but only for that reason. Anyone who comes up with a better solution will get a drink (more like another drink) on me at the Tableau Customer Conference.
So here is how I do it: A function (or calculation in Tableau), can output at most one value for any given input. I’d like to break this rule and output 2 numbers so that I have not only the previous value, but also the one before. The trick is, I didn’t specify what type this output should be. Since I can convert between types, there is no reason why I can’t output a vector as a string, concatenating numbers together separated by a delimiter, and then grab the appropriate value from the vector to display as a measure Feeling sick to your stomach yet?
Here is the Fibonacci sequence being dynamically computed in Tableau Public (the source data has 10 rows).
Fractals
I’ll refer to Wikipedia for a general description of fractals, so I can stay more or less on Tableau. Basically, many fractals can be thought of as a visual version of an iteration process.
The first example is a Serpinski Carpet. Starting with a square, remove the center 9th (in the tic-tac-toe sense). This leaves 8 smaller squares. Remove the center 9th from each of these leaving 8×8=64 smaller squares. Now keep on removing squares forever. The source data has 32 rows:(2 for each the x and y axis) * (2 for the axis along which the iteration takes place) * (4 because I’m using polygons to avoid needing to tinker with the size slider each time I change the maximum number of iterations).
Here are a few iterations of the Serpinski Carpet as an animated GIF:
Next up is the Mandelbrot Set. The Mandelbrot set is produced via recursion on the complex plane. Alternatively, this can be thought of as a 2 dimensional real iterative process, with a bit more complexity in the formula: Starting from a point (u,v) we perform a 2 dimensional iteration:
A point is out if the sequence of points diverges (i.e. gets further and further from zero). The remaining points form the Mandelbrot set. If the distance from zero ever becomes greater than 2, then the sequence is certain to diverge. This fact is often used to color the complement recording the first iteration where this distance was greater than 2. In practice only finitely many iterations can be performed (and with finite accuracy) so this is really a sketch. The viz is parameter driven, so the center, zoom, number of iterations and resolution can be adjusted. There are only 8 rows in the source data, which is not too shabby for an infinitely complex mathematical structure. Note: Tableau 8.1 added a pass-through to R, so in theory these computations could be handled outside Tableau or the data could be pre-processed as Bora Beran recently blogged. I’ve yet to realize a performance improvement from using the R pass-through for this iteration, though at this point I might not be doing it right, it definitely seems like a more scalable approach than my converting to text trick.
For the next workbook I’d suggest wearing ChromaDepth 3D glasses. Where does one get ChromaDepth glasses? All over! Crayola sells 3D coloring books in most drug stores I’ve looked in (Wallgreens, CVS, Duane Reade), toy stores, craft stores, Amazon, Ebay, and even a lot of grocery stores have them lately. The only problem with the Crayola ones is that they are made for children, so they may not fit on your head (until you break the arms off). I ordered a few pairs recently online that are made for grownups and am pretty happy with the quality (I got the ChromaPro 3D), you can even get custom printed ones. So go ahead and get some glasses. Off you go…
3D
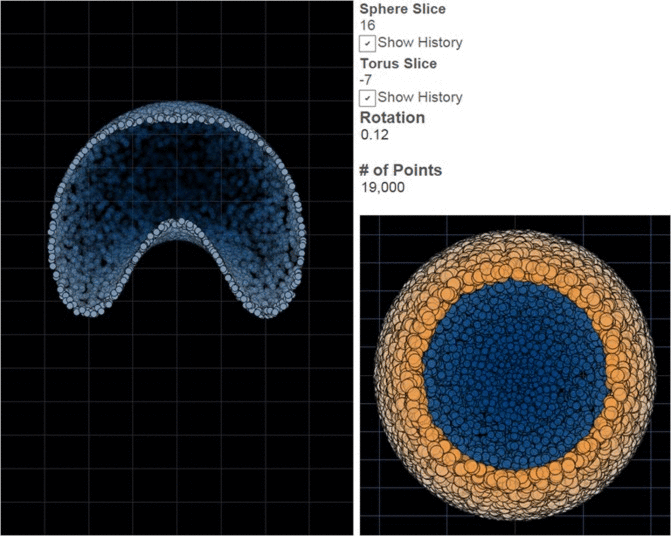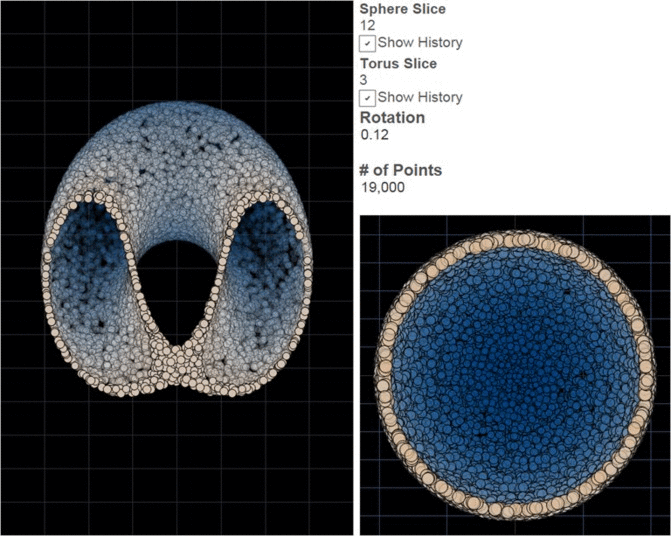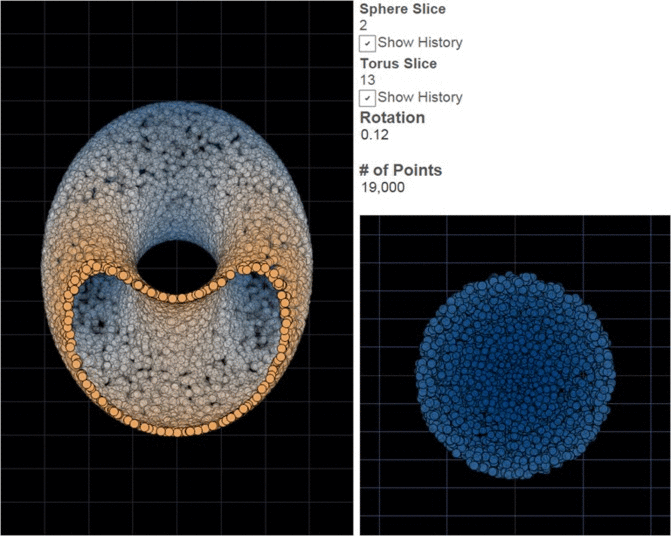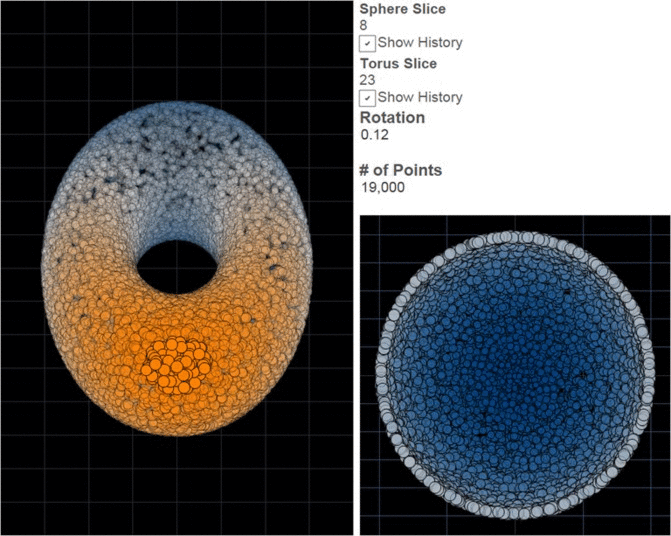
There are many options for doing genuine 3D on your computer, but most require either a significant investment in technology or image processing in order to create separate images for the left and right eyes and make each of these images available to only one eye. ChromaDepth is different in that each lens is essentially a weak prism oriented in opposite directions. You’ve probably seen a prism separate light into a rainbow; the glasses similarly scatter light slightly by wavelengths. Moving red slightly to the center makes it appear closer to the viewer, then orange, yellow, green, blue, purple (I find the response to be a bit flat at the ends of the spectrum, so I go from orange to blue). The illusion becomes more impressive with a dark background and if 2d cues for distance are also incorporated, i.e. farther things are relatively smaller and close things obscure farther things when they get in the way. One beautiful property of ChromaDepth is that because color is being used to encode distance, the images can be viewed without special glasses. They won’t be 3D without the glasses, but they won’t be fuzzy either. So if you skipped intermission and you don’t have 3D glasses, have a look anyway, you won’t break anything. There are only 2 rows in the source data.
Who needs a million rows? I do, and then some, but using Tableau to create rich visualizations based on a dataset with only a handful of rows is probably not something anyone intended. I think it hints at a deeper truth that in the age of big data is often overlooked. A picture can be worth a thousand words; it isn’t always, and even when it is there is a big difference between a thoughtful essay and a bag with a thousand words in it. The excitement for me is in finding something unexpected; looking sideways at a dataset and learning something I wouldn’t have guessed and sharing that story with others. Surprises can come in very small packages and the richness of a story isn’t a function of the number of rows any more than it is the number of semicolons; but I do love me some semicolons.
Here are links to all the workbooks referenced in this post: