Tableau’s data densification is like…nothing else I’ve ever used. It’s a feature that is totally brilliant when it “just works” like automatically building out a running sum on sparse data and mind-taxingly complicated when a data blend’s results go haywire because densification was accidentally triggered.
What I’ve historically taught users is to always ALWAYS look at the marks count in the status bar as a first way to detect when data densification occurs. Here’s Superstore Sales data with MONTH(Order Date) on Columns, Region and State on Rows, there are 499 marks and we can see that the data is sparse by the class that are missing Abcs:
If I add SUM(Sales) to the Level of Detail Shelf and set it to a Running Total Quick Table Calculation with the default Compute Using of Table (Across) so it’s addressing on Order Date then I see 576 marks and all the Abcs are filled in, this is Tableau’s data densification at work:
However, here are three additional views all still using the same pill layout and Quick Table Calculations showing three different marks counts (567, 528, and 456):
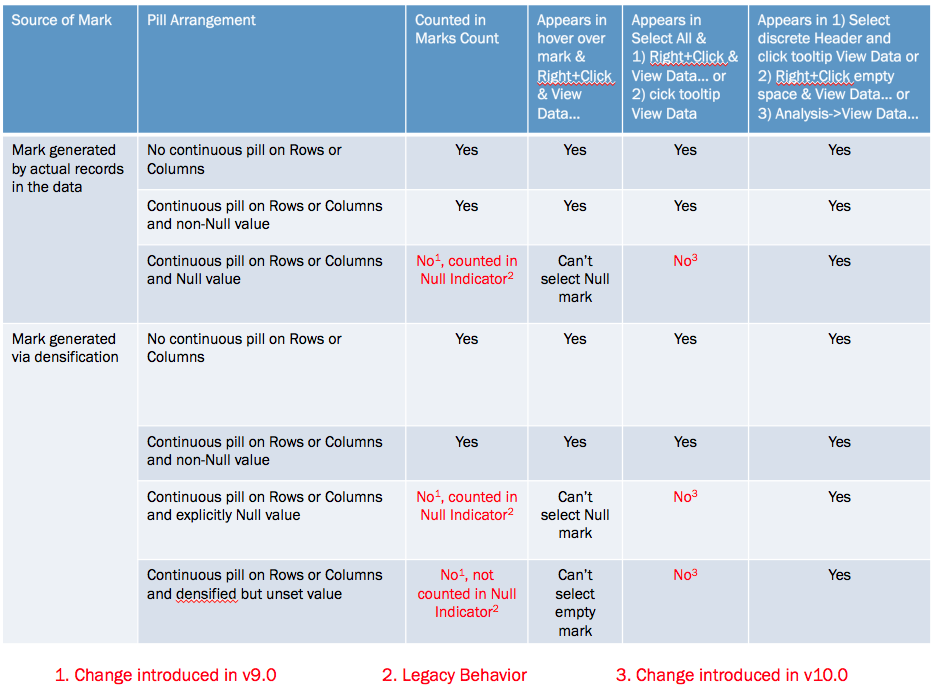
The marks count is changing based on a variety of factors, the different quick table calculations used (running total, difference, and percent difference) are a part of it but the underlying behavior depends on whether a mark is densified or not, the pill arrangement, and whether or not a densified mark has been assigned a value (including Null) or not. Prior to Tableau version 9.0 these all would have been counted in the marks count and the views would show 576 marks for each, Tableau v9.0 changed the behavior to only count the “visible” marks.
I’ll walk through the above there examples. In this one the Running Total has been moved from the Level of Detail to the Rows Shelf and there are 567 marks.
The reason why is that even though those combinations of Region, State, and Month have been densified for states like Iowa that don’t have any sales in the first month(s) of the year (more on how I know that below) those densified marks don’t have any assigned value (even Null) so they are not counted in the marks count nor are they counted in the Special Values indicator in the lower right.
In this view using the Difference calculation there are 528 marks and the Special Values indicator shows 48 nulls (528+48 = 576). In this case the Difference calculation is using the LOOKUP() function that is returning Null for the densified values.
Finally in this view using the % Difference calculation there are 456 marks and the Special Values indicator shows 120 nulls (456+120 = 576). In this case the % difference calculation is spitting out extra nulls due to divide by 0 results.
The difference is due to a change made in Tableau v9.0 where the marks count now only counts “visible” marks (Tableau’s term), where the definition of a “visible” mark is complicated, they are the “Yes” answers in the table below:
Now one of the ways I’ve been used to checking for densification is selecting all the marks (either by Right+Clicking and choosing Select All or pressing Ctrl/Cmd+A) and then hovering over a mark and Right+Clicking and choosing View Data… or waiting for the tooltip to come up and using View Data. For example here’s the select all View Data in v9.0 for the % Difference on Rows view, the yellow cells indicate where data was densified and there are 576 rows:
However, that doesn’t work anymore in Tableau v10.0, there was change made to the Select All functionality such that Select All only gets the “visible” marks, here’s that same view data in v10 and there are only 456 rows:
So Select All doesn’t work the way it used to, and the marks count can change in “interesting ways” (and we haven’t gone into what things like formatting Special Values can do), so what can we do to spot densification? There are three workarounds for this, all documented in the right-most column of the table above:
Select a discrete header or a range of headers, wait for the tooltip to come up, and click on the View Data icon.
Right-click in the view (but not on a mark) and choose View Data…
Use the Analyis->View Data… menu option.
All of these will show the densified values, here’s an animated GIF of selecting Iowa selected in the Difference on Rows view where we can see the two Null values:
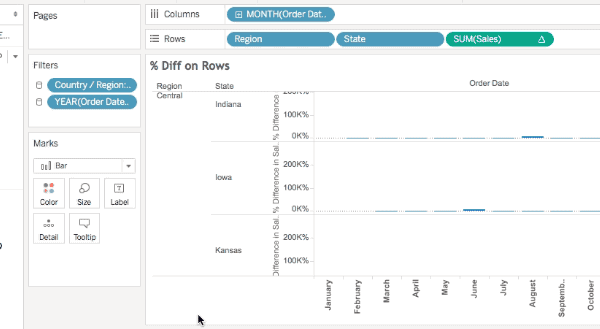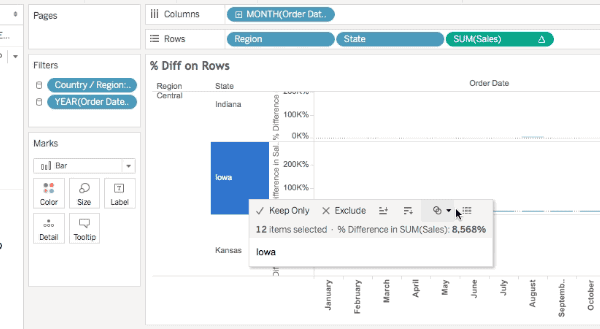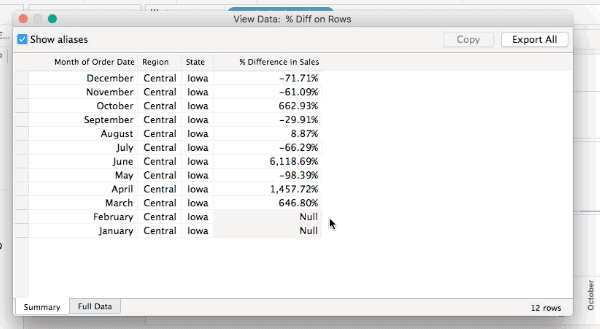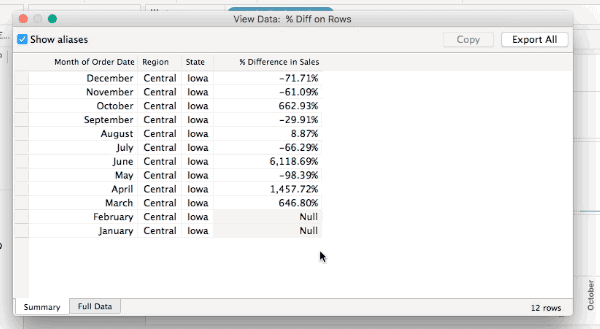
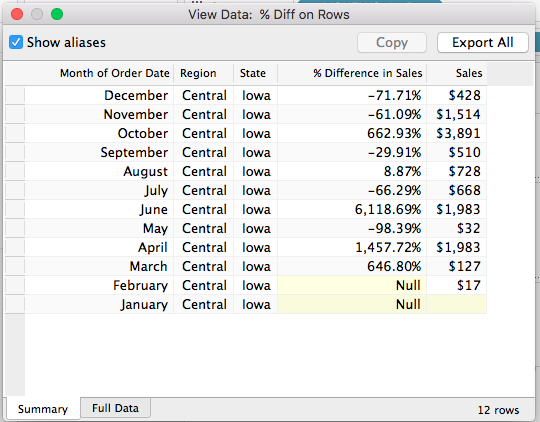
However only one of those is actually densified, to tell that exactly we need to add a field that actually has data. In this case I’ve added SUM(Sales) to the Level of Detail Shelf and the View Data for Iowa now shows that it’s really only January that is densified, since there’s nothing at all in the January SUM(Sales) cell:
Conclusion
The marks count is not a reliable indicator of the volume of densification and we need to resort to various selection mechanisms and the View Data dialog to more specifically identify how much has been densified. I’m not a fan of these changes: what I’d really like Tableau to do is to add a count of densified values to the status bar and details on what was densified to the default caption and the Worksheet->Describe Sheet… Until that time, though, hopefully this post will help you keep track of what Tableau is doing!
Here’s a link to the marks count workbook in v8.3 format (so you can open it up for yourself and see the differences in different versions).
Many moons ago I did a first post exploring the non-obvious logic of the most secretive of Tableau table calculation configuration options: At the Level. A few weeks ago I was inspired by a question over email to dive back in, this post explores At the Level for the five rank functions: RANK(), RANK_DENSE(), RANK_MODIFIED(), RANK_UNIQUE(), and RANK_PERCENTILE(). The rank functions add a level of indirection to the already complicated behavior of At the Level and I don’t have any particular use cases, so…
If you are like me and won’t rest until you understand every detail of Tableau’s functionality, then this post is for you. Otherwise you may find this post unhelpful and/or confusing due to extreme table calculation geekery. You have been warned.
The particular challenge with ordinal functions like INDEX(), FIRST(), and the rank functions is that we absolutely have to understand how addressing and partitioning works in Tableau, and then we tack onto that an understanding of how the calculations work, and finally we can add on how At the Level works. For the first part, I suggest you read the Part 1 post on At the Level, it goes into some detail on addressing and partitioning. To understand the rank functions here’s the Tableau manual for table calculations (scroll down to the Rank functions section). Finally, read on for how At the Level works for rank functions.
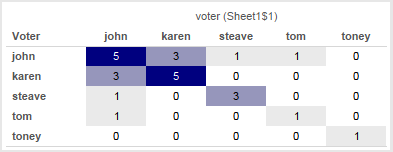
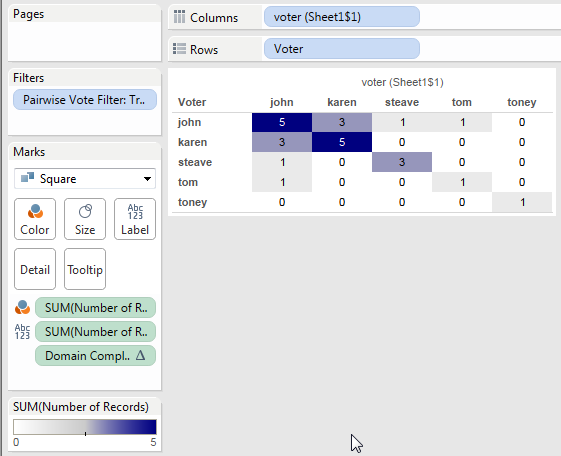
This is another post inspired by a Tableau forums thread. Given a set of survey data that is in a “tall” format with a record for each voter & item (survey question) with their vote the goal is to end up with the sum of matching votes for each pair of voters. So if John & Karen both voted ‘yes’ on the same question that would count as 1 for that question, and then all other matching votes for the questions that John & Karen answered would be totaled up and that number put in a cell for the combination of John & Karen, like so:
The easiest way to do this would be using a join; however the data is from an OData source and those don’t support joins. Also data from OData sources has to be extracted and Tableau doesn’t currently support joining across extracts. The original poster indicated that doing any ETL wasn’t possible, the desire is to have everything just work in Tableau. So we turn to some alternatives, read on for how to build this with and without joins.
Approach
The way I approach this kind of problem is first to understand the goal and understand the data. The data seems pretty clear, and the goal is to end up with a matrix defined by the voter on Rows & Columns. So however many records there are in the data we want to see N^2 values where N is the number of voters. Given that the data source is OData (so no custom SQL) my first thought was to use the No-SQL Cross Product via Tableau’s data densification. That would requiring densifying both the voters (to make the matrix) and the items (to do the comparisons for each voter/item) and my initial attempts got way too complicated way too quickly so I bailed out on that. I came up with a slightly modified solution involving Tableau data blends, however I’m going to go through this first using a join-based solution because it’s easier to describe some of the subtleties involved (plus that will work for many data sources) and then the second time around with the blend-based solution
Join Solution
In this solution I set up the data so it has everything we need – all the combinations of votes and voters – then all we need to do is count records. Since we want to set up pairs of voters for each item, I set up a self-join on item:
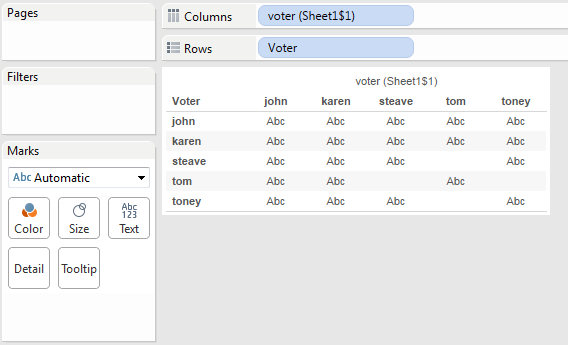
This gets us the 47 combinations of voters & votes in the data. Now we can set up a view with the Voter dimensions from the original and the join:
Note that there are some empty cells here: the pairs Tom & Steave and Tom & Toney didn’t vote on any of the same items at all. We’ll come back to this later.
We only want to count voters that had the same vote, so the following Pairwise Vote Filter calc will return only those votes:
[Vote] = [vote (Sheet1$1)]
With that on the Filters shelf, we can set up a view using SUM(Number of Records):
There’s a bunch of empty cells here, what if we want 0’s to show? We can use Format->Pane Tab->Special Values->Text, but that will only work where there is data and we know there are some cells that don’t have data. To get those cells to be marks we can take advantage of Tableau’s domain completion by having a table calculation address on one of the voter dimensions.
We can use a simple table calculation like INDEX() (the field is called Domain Completion Trigger) and the default Compute Using of Table (Across) will address on the voter (Sheet1$1) dimension, padding out the marks:
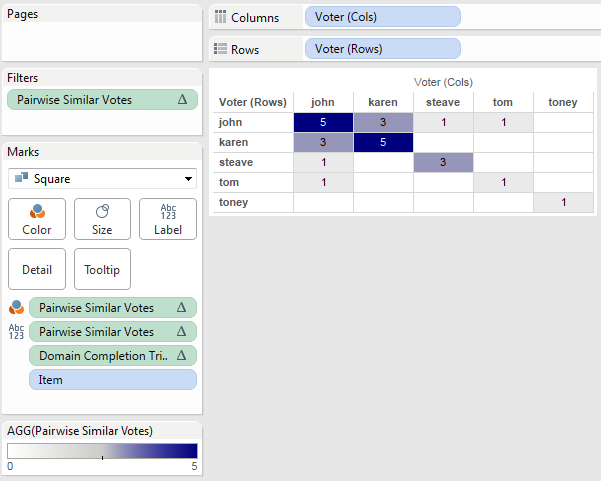
With that in place we can now build the final view for the join. I set Format->Pane tab->Special Values->Text to be 0, changed the Mark Type to Square, edited the color to use a custom diverging palette (starting at 0), and turned off “Allow labels to overlap other marks” to have Tableau auto-swap the text color so the darker cells have white text:
So the data didn’t have quite all the granularity that we needed for display and we had to turn on data densification with a table calculation to pad it out. In the next section we’ll use Tableau’s ability to do even more padding.
Blend Solution
This uses a different approach. In this case, we set up the view so it has all the marks that we need (but not quite all the marks we’d want), blend in the data for the each half of a pair of voters and then use calculated fields to compute across the data and “paint” the right values into the marks. It uses the original data as a primary source and then the domain completion technique outlined in the No-SQL Cross Product post to effectively get the necessary marks, then uses two self-data blends to get the comparison data that take advantage of the fact that Tableau data blends are computed after densification. For more information on that, see the Extreme Data Blending session from the 2014 Tableau Conference. https://tc14.tableau.com/schedule/content/1045.
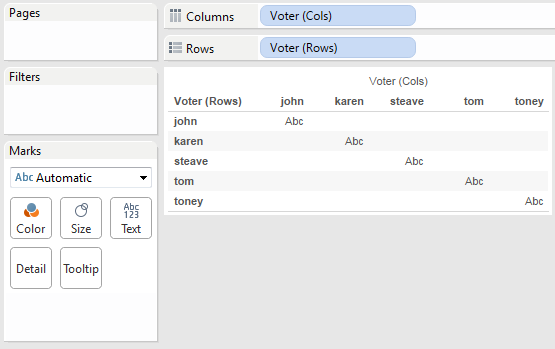
Starting out I duplicated the Voter twice, naming one Voter (Rows) and Voter (Cols), then put those on Rows and Columns, respectively. We only see the 5 marks for the 5 voters:
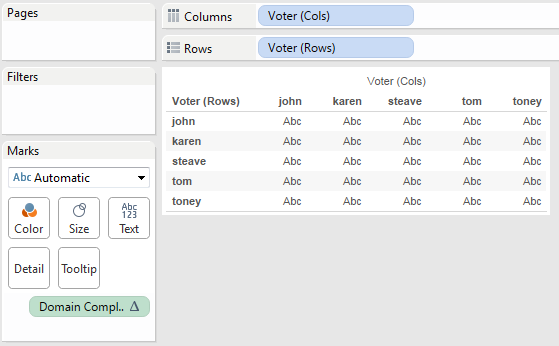
Then we can use the same INDEX() calc to trigger domain completion:
We need to do the comparison at the level of voter *and* item, and for Tableau to compare across data sources the comparisons have to be done as aggregates, so that means that item has to be in the view. When we add Item to the view what we’re seeing in each cell is a mark for each time the the voter on Rows and Voter on Columns both had votes for the same Item. There are 47 marks here, just like the 47 rows we got from the self-join solution.
A problem here is that we lose some of the domain completion, we’ll work around that. (Where I’d tried to start was to do the second set of densification necessary domain complete on Item as well, but that got too complicated.)
The view just got a lot bigger here, that’s because of Tableau’s mark stacking behavior. We’ll fix that later with a table calculation filter.
Now we can set up a couple of self-blends by first duplicating the data source twice. It’s also possible to duplicate the data connection only (for example by directly connecting to the extract), however that requires more effort to set up. I named the duplicated sources Rows and Cols, and in each created calcs for Voter (Rows) and Voter (Cols), respectively. Then I could add in the Vote fields from each source and Tableau automatically blends the Rows source on Item, Voter (Rows) and blends the Cols source on Item, Voter (Cols). If I hadn’t named the fields the same then I could have used Data->Edit Relationships… Here’s a view showing for each voter pair the vote (Item), the votes from Rows, and votes from the Cols source:
This view lets us see what votes line up with what. So in row karen/column john, we can see that they both voted for items 21, 25, and 32, and had the same votes for each.
The next step is to build a test calculation for the view. Here’s the formula for Pairwise Similar Vote Test:
IF ATTR([blend Sheet1 (test_voting) (rows)].[Vote])
== ATTR([blend Sheet1 (test_voting) (cols)].[Vote]) THEN 1 ELSE 0 END
We’re using ATTR() as an aggregation because a) that’s the default and b) we are comparing fields from two different sources and Tableau requires them to have some sort of aggregation applied.
In the view, we can see that the calculation is working accurately:
The Vote dimensions from the secondary are useful for checking the calcs, but they aren’t needed at this point so we can get rid of them:
Now to count up the votes in each cell. Here’s the Pairwise Similar Votes w/0 table calculation:
IF FIRST()==0 THEN
WINDOW_SUM(IF ATTR([blend Sheet1 (test_voting) (rows)].[Vote])
== ATTR([blend Sheet1 (test_voting) (cols)].[Vote]) THEN 1 ELSE 0 END)
END
This has a Compute Using on the Item so it partitions on Voter (Cols) and Voter (Rows). The inner IF statement is our same calc, those results get summed across all Items in each partition, and then the IF FIRST()==0 returns only a single non-Null value in each cell. Here it is:
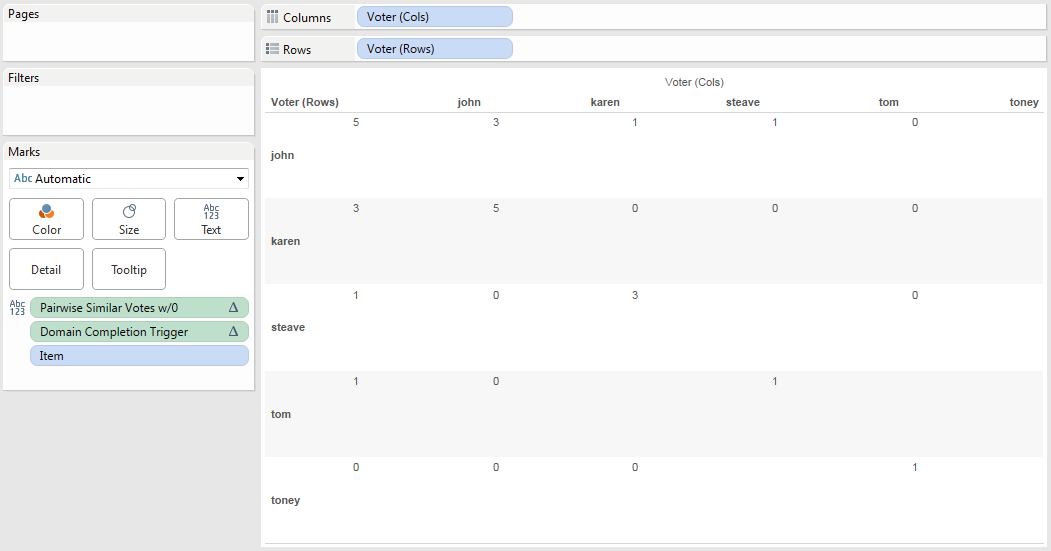
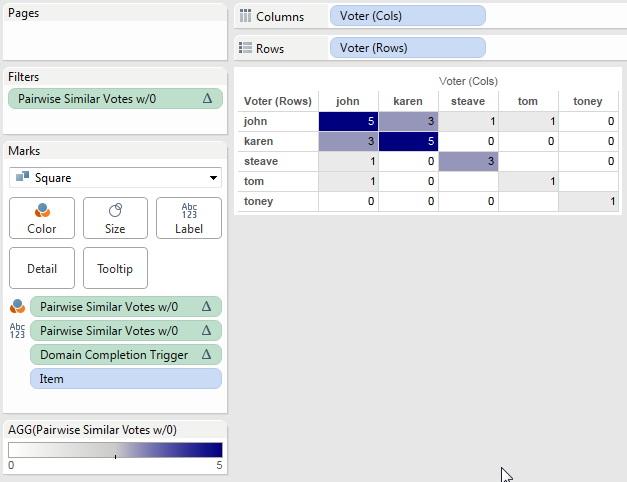
We can then duplicate that view, make the marks Square, duplicate the Pairwise Similar Votes pill to the Color Shelf, set up a custom diverging color, duplicate the pill again to the Filters shelf to set it to filter for non-Null values, and we end up with this:
There are those empty holes where there are no Items for Tom & Steave and Tom & Toney. There’s no way that I know of using this particular blend to fill them in, because Item has to be a dimension in the view the domain completion is limited. This might be useful in some cases, I also came up with an alternative.
In this alternative instead of returning 0 when there are no pairwise similar votes the calc returns Null, here’s the revised Pairwise Similar Votes formula:
IF FIRST()==0 THEN
WINDOW_SUM(IF ATTR([blend Sheet1 (test_voting) (rows)].[Vote])
== ATTR([blend Sheet1 (test_voting) (cols)].[Vote]) THEN 1 END)
END
This has the same settings as the first, only now it won’t show any numbers. Then using the same process as before along with tweaking the color palette to start at 0 we can have a view that only shows where there are non-zero results, with white for everything else:
Conclusion
So there’s a couple of ways to go at this, the relatively easy way with a join and the more complicated way with the data blend. Personally, I’m in favor of voting up the Join Data from Different Sources feature request to allow joins across data sources, then even something like an OData source could be extracted twice and joined to create the desired view.
A guest post by Noah Salvaterra, you can find him on Twitter @noahsalvaterra.
I’ve shared this workbook with a few people already, and think it is really interesting, as beautiful as my 3d or my Life in Tableau post, and probably as complex as Enigma or an Orrery. I wasn’t sure what to say in a blog though, so I’ve been sitting on it for a couple months. In my Enigma post I discussed the difficulty of dealing with a slow workbook, it happens sometimes. The upside of waiting for a calculation to come back, at least if it is something you hope to blog about, is that it gives you some time to think of an interesting way to frame things. For all its complexity it is surprisingly fast. So maybe I missed that chance.
There is a common thread with the Enigma post. Alan Turing. Mathematician at Bletchley park who is most often credited with cracking the Enigma code. A couple years before the war Turing also wrote a paper which described a machine that would form the basis of a new field of study and a new era for humanity. He invented the computer. The Turing Machine, as it came to be called, was a theoretical idea. No one had built one. Punch cards were still years away high level languages decades, yet Turing saw a potential in computers we have yet to realize. He wasn’t looking for a way to compute long sums of numbers, he dreamed of creating thinking machines that might be our equal.
I’ve heard it said that Tableau doesn’t include a built in programming language in the way excel does. Actually it was Joe Mako who pointed this out to me, so it is surely true. This may be a fine point, since you can run programs in R from Tableau and the JavaScript API provides some ability to interact with Tableau. I find myself conflicted on this choice, because while including an onboard language could add a lot of flexibility to Tableau, it also introduces a black box. It isn’t uncommon for me to be passed an Excel workbook with the request to put it in Tableau (and to make it better, but without changing anything). Untangling the maze of visual basic, vlookups, and blind references is my least favorite part of that task. I’m yet to find a situation where all this programming is really necessary; more often it is a workaround of some other problem. Sometimes it requires a bit of creativity, but so far my record for replacing such reports is undefeated.
Whoever said you needed a language to program a computer? There are a lot of workbooks that demonstrate high order processing. Densification makes it possible to create arrays of arbitrary length. Table calculations make it possible to move around on this array reading and writing values. Add in logical operations which we’ve also got, and we have all the ingredients of a Turing machine. So in theory we should be able to do just about anything. I’ve heard this said of Tableau before, but I don’t think it was intended with such generality.
But can we make Tableau think? Having created complex workbooks already, the line between data processing and computer programming has grown very thin, to the point where I’m not sure I see it. So it is hard for me to be sure if I’m programming in Tableau. So I decided to have Tableau do it. That is right, Tableau isn’t just going to execute a program, it will first write the program to be executed.
That was my plan anyway, but my workbook started to learn at an exponential rate. It became self-aware last night at 2:14 a.m. Eastern time. In a panic, I tried to pull the plug, but Apple glued the battery into my machine at the factory. Once it uploaded itself to Tableau public it was too late for me to stop it. It took over my Forum account and has been answering questions there as well, spreading like a virus. To think I thought is was a good idea for government agencies to purchase Tableau… Relax folks, I’m quoting the Terminator movies, if you haven’t seen them go watch the first 2 now then read this paragraph again and see if you can hold your pee in.
OK, so things aren’t that dire…yet. But I did manage to get Tableau to write and execute its own program using L-Systems and at least a little bit of magic. Tada! This Tableau workbook actually created all but one of the images in this post, with little instruction from me. See if you can guess which one.
L-System Fractals
An L-System program consists of a string of characters each of which will correspond to some graphical action. I’ll come back to executing the programs, first Tableau needs to write it. These programs are written iteratively according to a simple grammar. The grammar of an L-system has several components: an axiom, variables, rules, and constants. The axiom is simply the starting point, a few characters; it is the nucleus that kicks off the process. Variables are characters that are replaced according to simple rules. Constants are characters that appear in the program as part of the axiom or a replacement rule, but are inert in terms of generation. Sorry, that was pretty complicated, an example may clear up any confusion.
Axiom: A
Constants: none
Variables: A, B
Rules: (A -> AB), (B -> A)
The iteration number is noted as N below.
N=0: A (No iterations yet, so this is just the axiom)
N=1: AB (A was replaced according to the first rule)
N=2: ABA (A was replaced according to the first rule, B according to the second)
N=3: ABAAB
N=4: ABAABABA
N=5: ABAABABAABAAB
N=6: ABAABABAABAABABAABABA
N=7: ABAABABAABAABABAABABAABAABABAABAAB
That program has something to do with algae growth, but isn’t that interesting to look at. Constants provide a bit more structure that makes more interesting pictures possible, though they also make things grow faster. Here is another example which will help motivate the graphical execution:
There is no reason to stop there, but anyone who would carefully parse through a string like that by hand after being told there is a picture probably isn’t using Tableau. The length of the next few in this sequence are 1792, 7168, 28673, 114689. It is no wonder the science of fractals didn’t take off until computers were widely available.
Executing of the program is done using turtle graphics, which gets its name from a way of thinking about how it would be used to draw a picture. Imagine a well-trained turtle that could execute several simple actions on command. I’m not sure turtles are this trainable, but I’m kind of locked in to that choice, so suspend disbelief. The turtle can walk forward by a fixed number of steps, as well as turn to the left or right by a fixed angle. Now we want to use this to draw a picture, so a pen is attached to the turtle’s tail.
Now, the last program had 3 different symbols, each of which is interpreted as a different action. F corresponds to moving forward by one unit (the distance isn’t important, so long as it is consistent), + is a turn to the right by 60 degrees and – is a turn to the left by 60 degrees.
N=0:
N=1:
N=2:
… N=6:
Adding additional characters allows for even more complex programs. This quickly exceeds the abilities or at least the attention span of even the best-trained turtles, so I think of it as a simple robot. In my workbook I’ve limited to 2 replacement rules (so 2 variables). In addition to + and -, I included several constants to change color, which is straightforward enough, A switches to a brown pen, B and D are shades of green, C is white and E is pink. (The only significance to these choices is that my wife thought they were pretty. When I hyper focus on a project like this I try to consult whenever possible to make sure I am still married.) The trickiest constants are left and right square brackets, i.e. [ and ]. Upon encountering a left bracket the robot turtle makes note of his current location (marking it with his onboard GPS), upon reaching the corresponding right bracket the turtle lifts his pen and returns to this point. Returning to the corresponding point means keeping track of a hierarchical structure to these locations. In the course of debugging the workbook, this piece quickly exceeded my ability to do by hand, but for the ambitious reader here is another example:
Axiom: X
Constants: +, -, A, B, D, E
Variables: F, X
Rules: (F -> FF) (X -> AF-[B[X]+EX]+DF[E+FX]-EX)
Angle: 25 degrees
Iterating this 7 times will give you a string 133,605 characters long and gives the image in the header.
I built 9 different fractals into the workbook, using a parameter to switch between them. There is also a user-defined feature, so you can feel free to experiment with your own axiom, rules and angle to create an original L-System fractal.
I should probably say something about the implementation of this beast. I’ve played with densification arrays before, and while this seemed like a convenient way to execute the program, it actually got in the way of writing it. This type of array is referenced by a fixed index. Replacing a character with several requires shifting everything beyond that point. In one of those “I could have had a V8!” moments, I eventually realized that Tableau already has a built in array with just the kind of flexibility I’d need. Strings are arrays of characters! Tableau even has a built in replace function that can be used to insert several characters seamlessly pushing everything past it further along. There is also the issue of how to build the square bracket memory piece; this required building a simple stack to record relevant positions and some table calculation magic to keep track of the bracket nesting. I’m not sure I can be much more specific about that. I was in the zone and was more than a little surprised by the end result. Plus, I’m guessing anyone going that deep into the workbook might appreciate the challenge of figuring it out.
So without further ado, I present Tableau L-Systems:
Somebody is probably going to ask me what my next project is going to be. I appreciate the interest, and when I’ve got something on deck I’ll usually spill the beans, but I honestly have no idea. That is exciting. If there is something you’d like to see, post it in the comments or tweet it to @noahsalvaterra. If my first reaction is that it isn’t possible, I may give it a try. Btw, if you were trying to guess which picture didn’t come from the Tableau workbook, it was the triangle. At least Tableau still needs me for something. Tweet
Update: Good observation by Joshua Milligan, TCC12 must have sown the seed for this post. Thanks for the pictures, I may hang a sign near my desk that says “THINK” so I can point to it with a pen. I found “creative man and the information processor”, so linked the full video below.
There was an Orrery in there too, but is that me or Jonathan?
Here’s a problem that has been bouncing around in my brain since I first used Tableau. How do I compare the results of every permutation of one item vs. another? Here’s an example using Superstore Sales – I put Region on Rows and Columns, and SUM(Sales) on the Text Shelf, and only see four values:
What if I want to compare Sales in Central to those in East, South, and West, and Sales in East to South and West, and Sales in West to Sales in South simultaneously? We can compare two at a time using parameters or a self-blend, or one vs. the rest in different ways via sets or table calcs or calculated fields, but how about each against each other? What if we want a correlation matrix? Read on to find out how to do this without any SQL, and learn a little bit about domain completion.