Tableau’s data blending feature is great for mashing up data sets from a whole variety of data sources. Want do download local weather data from Weather Underground to see how precipitation affects your coffee sales in Seattle? Sure!
However, blending can be a little tricky to set up to get the appropriate level of detail in the view, especially when you need to blend at one level of granularity and aggregate at another. In this post, I’ll walk you through a technique for doing this in v7, and how version 8 makes this process easier, using an example drawn from my own work that adds a level of complexity because the data is sparse. This makes a great case study for how to integrate different features of Tableau to create the desired view.
Patient Falls Dashboard
As part of improving patient safety, we track all patient falls in our healthcare system, and the number of patient days – the total of the number of days of inpatient stays at the hospital. Every month report we report to the state our “fall rate,” a metric of the number of falls with injury for certain units in the hospital per 1000 patient days, i.e. days that patients are at the hospital. Our annualized target is to have less than 0.7 falls with injury per 1000 patient days.
A goal for our internal dashboard is to show the last 13 months of fall rates as a line chart, with the most recent fall events as a bar chart, in a combined chart, along with a separate text table showing some details of each fall event. Here’s the desired chart, with mocked-up data:

On the surface, blending this data seems really straightforward. We generate a falls rate very month for every reporting unit, so use that as the primary, then blend in the falls as they happen. However, this has the following issues:
- Sparse Data – As I’m writing this, it’s March 7th. We usually don’t get the denominator of the patient days for the prior month (February) for a few more days yet, so there won’t be any February row of measure data to use as the primary to get the February fall events to show on the dashboard. In addition, there still wouldn’t be any March data to get the March fall events. Sometimes when working with blend, the solution is to flip our choices for the primary and secondary datasource. However, that doesn’t work either because a unit might go for months or years without a patient fall, so there wouldn’t be any fall events to blend in the measure data.
- Falls With and Without Injury – In the bar chart, we don’t just want to show the number of patient falls, we want to break down the falls by whether or not they were falls with injury – the numerator for the fall rate metric – and all other falls. The goal of displaying that data is to help the user keep in mind that as important as it is to reduce the number of falls with injury, we also need to keep the overall number of falls down as well. No fall = no chance of fall with injury.
- Unit Level of Detail – Because the blend needs to work at the per-unit level of detail as well as across all reporting units, that means (in version 7 at least) that the Unit needs to be in the view for the blend to work. But we want to display a single falls rate no matter how many units are selected.
Sparse Data
To deal with issue of sparse data, there are a few possible solutions:
- Change the combined line and bar chart into separate charts. This would perhaps be the easiest, though it would require some messing about with filters, hidden reference lines, and continuous date axes to ensure that the two charts had similar axis ranges no matter what. However, that would miss out on the key capability of the combined chart to directly see how a fall contributes to the fall rate. In addition, there would be no reason to write this blog post. 🙂
- Perform padding in the data source, either via a query/view or Custom SQL. In an earlier version of this project I’d built this, and maintaining a bunch of queries with Cartesian joins isn’t my favorite cup of tea.
- Building a scaffold data source with all combinations of the month and unit and using the scaffold as the primary data source. While possible, this introduces maintenance issues when there’s a need for additional fields at a finer level of detail. For example, the falls measure actually has three separate fall rates – monthly, quarterly, and annual. These are generated as separate rows in our measures data and the particular duration is indicated by the Period field. So the scaffold source would have to include the Period field to get the data, but then that could be too much detail for the blended fall event data, and make for more complexity in the calculations to make sure the aggregations worked properly.
- Do a tiny bit of padding in the query, then do the rest in Tableau via Show Missing Values aka domain padding. As I’d noted in an earlier post on blending, domain padding occurs before data is blended so we can pad out the measure data through the current date and then include all the falls. This is the technique I chose, for the reason that padding one row to the data is trivial and turning on Show Missing Values is a couple of mouse clicks. Here’s how I did that:
In my case, the primary data source is a Microsoft Access query that gets the falls measure results from a table that also holds results for hundreds of other metrics that we track. I created a second query with the same number of columns that returns Null for every field except the Measure Date, which has a value of 1/1/1900. Then a third query UNION’s those two queries together, and that’s what is used as the data source in Tableau.
Then, in Tableau, I added a calculated field called Date with the following formula:
//used for padding out display to today
IF [Measure Date] == #1/1/1900# THEN
TODAY()
ELSE
[Measure Date]
END
The measure results data contains a row per measure, reporting unit, and the period. These are pre-calculated because the data is used in a variety of different outputs. Since in this dashboard we are combining the results across units, we can’t just use the rate, we need to go back to the original numerator and denominator. So, I also created a new field for the Calculated Rate:
SUM([Numerator])/SUM([Denominator])
Now it’s possible to start building the line chart view:
- Put the Month(Date) – the full month/year version as a discrete – on Columns, Calculated Rate on Rows, Period on the Color Shelf. This only shows the data that exists in the data source, including the empty value for the current month (March in this case):

- Turn on Show Missing Values for Month(Date) to start domain padding. Now we can see the additional column(s) for the month(s) – February in this case between January to the current month that Tableau has added in:

- Now for some cleanup steps: for the purposes of this dashboard, filter Period to remove Monthly (we do quarterly reporting), but leave in Null because that’s needed for the domain padding.
- Right-click Null on the Color Legend and Hide it. Again, we don’t exclude this because this would cause the extra row for the domain padding to fail.
- Set up a relative date filter on the Date field for the last 13 months. This filter works just fine with the domain padding.
Filtering on Unit
Here’s a complicating factor: If we add a filter on Unit, there’s a Null listed here:
I’d just want to see the list of units. But if we filter that Null out, then we lose the domain padding, the last date is now January 2013:
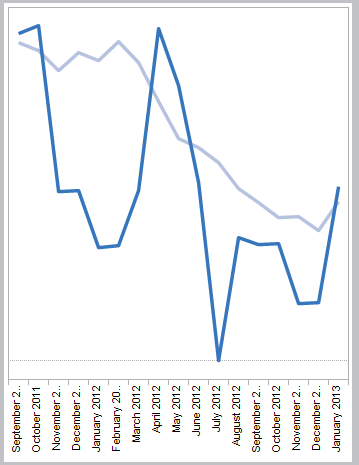
One solution here would be to alter the padding to add a padding row for every unit, instead of just one unit. Since Tableau doesn’t let us just hide elements in a filter, and we actually have more reporting units in our data than we are displaying on the dashboards, I chose to use a parameter filter because there are more reporting units in our production data than we are displaying on the dashboards, yet the all-unit rate needs to include all of the data. Setting this up included a parameter with All and each of the units, and a calculated field called “Chosen Unit Filter” with the following formula, that is set to Filter on False:
[Choose Unit] == "All" OR [Choose Unit] == [Unit]
Falls With and Without Injury
In a fantasy world, to create the desired stacked bars I’d be able to drag the Number of Records from the secondary datasource, i.e. the number of fall events, drag an Injury indicator onto the Color Shelf, and be done. However, that runs into the issue of having a finer level of detail in the secondary than in the primary, which I’ll walk through solutions for in the next section. In this case, since there are only two different numbers, the easy way is to generate two separate measures, then use Measure Names/Measure Values to create the stacked bars – Measure Values on Rows, and Measure Names on the Color Shelf. Here’s the basic calculation for Falls with Injury:
SUM(IF [Injury] != "None" THEN 1 ELSE 0 END)
We’re using a row-level calculated field to generate the measure, and a slightly different calc for Falls w/out Injury.
Unit Level of Detail
When we want to blend in Tableau at a finer level of detail and aggregate to a higher level, historically there have been three options:
- Don’t use blending at all, instead use a query to perform the “blend” outside of Tableau. In the case that there are totally different data sources, this can be more difficult but not impossible by using one of the systems or a different system to create a federated data source, for example by adding your Oracle table as an ODBC connection to your Excel data, then making the query on that. In this case, we don’t have to do that.
- Use Tableau’s Primary Groups feature “push” the detail from the secondary into the primary data source. This is a really helpful feature, the one drawback is that it’s not dynamic so any time there are new groupings in the secondary it would have to be re-run. Personally, I prefer automating as much as possible so I tend not to use this technique.
- Set up the view with the needed dimensions in the view – on the Level of Detail Shelf, for example – and then use table calculations to do the aggregation. This is how I’ve typically built this kind of view.
Tableau version 8 adds a fourth option:
- Tell Tableau what fields to blend on, then bring in your measures from the secondary.
I’ll walk through the table calculation technique, which works the same in version 7 and version 8, and then how to take advantage of v8’s new feature.
Using Table Calculations to Aggregate Blended Data
In order to blend the the falls data at the hospital unit level to make sure that we’re only showing falls for the selected unit(s), the Unit has to be in the view (on the Rows, Columns, or Pages Shelves, or on the Marks Card). Since we don’t actually need to display the Unit, the Level of Detail Shelf is where we’ll put that dimension. However, just adding that to the view leads to a bar for each unit, for example for April 2012 one unit had one fall with injury and another had two, and two units each had two falls without injury.

To control things like tooltips (along with performance in some cases), it’s a lot easier to have a single bar for each month/measure. To do that, we turn to a table calculation, here’s the Falls w/Injury for v7 Blend calculated field, set up in the secondary data source:
IF FIRST()==0 THEN TOTAL([Falls w/Injury]) END
This table calculation has a Compute Using of Unit, so it partitions on the Month of Date. The IF FIRST()==0 part ensures that there is only one mark per partition. I’m using the TOTAL() aggregation here because it’s easier to set up and maintain. The alternative is to use WINDOW_SUM(), but in Tableau prior to version 7 there are some performance issues, so the calc would be:
IF FIRST()==0 THEN WINDOW_SUM(SUM(Falls w/Injury]), 0, IIF(FIRST()==0,LAST(),0)) END
The ,0 IIF(FIRST()==0,LAST(),0 part is necessary in version 7 to optimize performance, you can get rid of that in version 8.
With a second table calculation for the Falls w/out Injury, now the view can be built, starting with the line chart from above:
- Add Measure Names (from the Primary) to Filters Shelf, filter it for a couple of random measures.
- Put Measure Values on the Rows Shelf.
- Click on the Measure Values pill on Rows to set the Mark Type to Bar.
- Drag Measure Names onto the Color Shelf (for the Measure Values marks).
- Drag Unit onto the Level of Detail Shelf (for the Measure Values marks).
- Switch to the Secondary to put the two Falls for v7 Blend calcs onto the Measure Values Shelf.
- Set their Compute Usings to Unit.
- Remove the 2 measures chosen in step 1.
- Clean up the view – turn on dual axes, move the secondary axis marks to the back, change the axis tick marks to integers, set axis titles, etc.
This is pretty cool, we’re using domain padding to fill in for non-existent data and then having a blend happening at one level of detail while aggregating to another, just for the second axis. Here’s the v7 workbook on Tableau Public:
Tableau Version 8 Blending – Faster, Easier, Better
For version 8, Tableau made it possible to blend data without requiring the linking fields in the view. Here’s how I build the above v7 view in v8:
- Add Measure Names (from the Primary) to Filters Shelf, filter it for a couple of random measures.
- Put Measure Values on the Rows Shelf.
- Click on the Measure Values pill on Rows to set the Mark Type to Bar.
- Drag Measure Names onto the Color Shelf (for the Measure Values marks).
- Switch to the Secondary and click the chain link icon next to Unit to turn on blending on Unit.
- Drag the Falls w/Injury and Falls w/out Injury calcs onto the Measure Values Shelf.
- Remove the 2 measures chosen in step 1.
- Clean up the view – turn on dual axes, move the secondary axis marks to the back, change the axis tick marks to integers, set axis titles, etc.
The results are the same as v7, here’s the v8 workbook on the Tableau Public v8 beta, with a bonus floating worksheet for the days since last injury:
What’s happening under the hood here is that whenever we click on the chain link icon, Tableau is adding that field as a GROUP BY clause to the query it issues to the secondary data sources. The data is then available at the level of detail needed for Tableau to appropriately compute the results.
Here’s how I see this new v8 blending as better than v7:
- There is only one less step, but no table calculations are necessary to get the view. This is a tremendous advantage because we can easily perform further aggregations using table calculations. (Once we use table calculations, further aggregations via nested table calculations can be more difficult to set up, so keeping the calculations at the level of regular aggregates is quite useful).
- Instead of having to go to the Data menu->Edit Relationships… to bring up a dialog box, we can control the blending relationships right in the Data window. Visually this keeps us “in the view” with our data, plus it’s fewer clicks.
- Even better, you can separately control the relationships that define the blend within each worksheet. There are cases with version 7 workbooks where we’d use duplicated data sources to make a variety of comparisons, for example to filter for certain units in the primary while retrieving a total across all units from the secondary, in v8 we can get away with a single duplicated data source.
There’s a set of other improvements for v8 blending in terms of filters, I’ll leave that one for another post!
Hi Jonathan,
A quick remark on filtering NULL values: if you do this as a data source filter instead of a normal filter, it may influence the domain padding in different ways. It’s at least worth experimenting with a bit.
-Robert
Pingback: Tableau Tips,Tricks,Best Practices - Data Blending - Jenny (Xiao) Zhang